Если вы инженер в крупной компании, а особенно если ваша организация поставляет свои услуги в виде SaaS-решений, то вам так или иначе придется решать задачу мониторинга работы всех ваших баз PostgreSQL. На них часто бывает завязан функционал, важный для компании с точки зрения финансовых рисков, поэтому крайне желательно организовать не только мониторинг, но и получение уведомлений, когда что-то идет не по плану (или пойдет в ближайшем будущем). Рассмотрим несколько способов, как это можно сделать:
- Самостоятельно, с использованием уже привычного стека Prometheus + Grafana (на котором можно будет строить мониторинг также и любых других ваших сервисов);
- Подключить сторонние open-source специализированные решения для мониторинга PostgreSQL;
- Использовать специализированные платные решения.
По каждому варианту поймем все плюсы и минусы, чтобы вы смогли более уверенно выбрать свой путь.
«Все сам» на Prometheus + Grafana
На связке Prometheus и Grafana строят свои системы мониторинга большинство компаний. В Prometheus есть готовые экспортеры для разных систем (это основное преимущество), и систему можно быстро развивать и настраивать под практически любые нужды. У вас не будет зоопарка разных инструментов, все вполне последовательно и единообразно, и научившись настраивать описанные ниже конфигурации, вы сможете собирать мониторинг абсолютно любых систем и сервисов в своей организации.
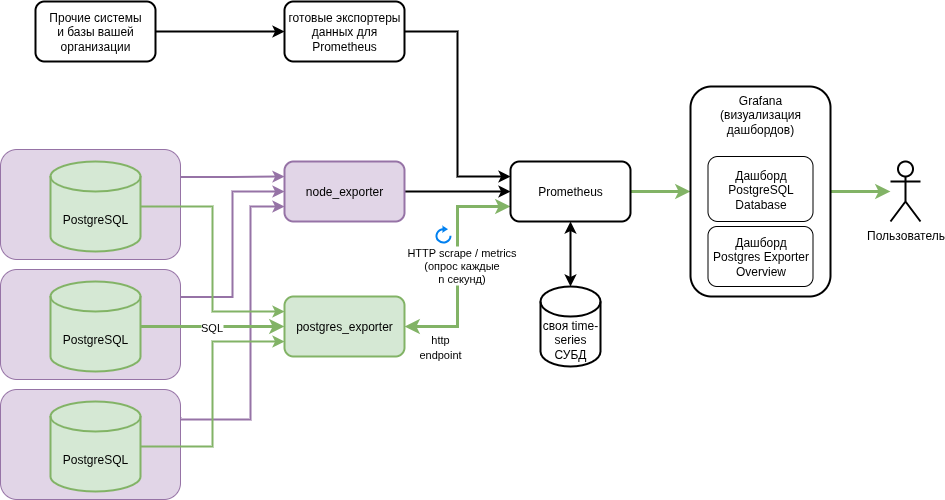
Чтобы это настроить, нужно пройти несколько шагов:
1. Установка и настройка postgresql_exporter на сервере PostgreSQL
Это агент, который будет собирать метрики PostgreSQL и отдавать их в Prometheus с локального endpoint (Prometheus опрашивает этот адрес каждые n секунд и складывает в свою time series БД).
Порядок работы postgres_exporter (равно как и любых других экспортеров для Grafana):
- Подключение к PG: postgres_exporter подключается к PostgreSQL через стандартное подключение (обычно TCP-соединение через порт 5432) и гоняет к нему стандартные SQL запросы за метриками. По правам он использует специально созданного pg-пользователя с правами на чтение информации о состоянии сервера (например, членство в роли pg_monitor);
- Сбор метрик: postgres_exporter выполняет SQL-запросы к системным представлениям (например, pg_stat_database, pg_stat_activity, pg_stat_replication, pg_stat_bgwriter, и т.д.).
Собираемые метрики конвертируются в формат Prometheus. Здесь важно иметь в виду, что если в PostgreSQL не устанавливать ряд дополнительных расширений, то набор метрик будет весьма скудным. Для сбора расширенной информации по метрикам, например по раздуванию таблиц, работе индексов и др. надо будет добавлять расширения и дополнительно конфигурировать postgres_exporter. Из расширений, в частности, полезно будет поставить следующие:
- pg_stat_statements - стандартное расширение для анализа производительности запросов и статистики;
- pg_buffercache для анализа буферов PostgreSQL.
Установка дополнительных расширений может "отъедать" ресурсы самого PostgreSQL, за этим важно следить. К тому же, простая установка этих расширений не заставит postgres_exporter собирать все необходимое, в его конфигурации надо будет добавлять необходимые запросы, и это займет у вас время.
Экспорт метрик
Сервис postgres_exporter предоставляет HTTP-endpoint (/metrics), с которого Prometheus регулярно собирает метрики (scrape - т.н. скраппинг через каждые n секунд).
Похожим образом работают все другие виды экспортеров для prometheus. У него есть масса различных экспортеров для разных систем, в частности mysql_exporter, mongodb_exporter, redis_exporter и др.
Для сбора метрик самого хоста вам придется дополнительно установить и настроить node_exporter, который работает схожим образом
После установки postgres_exporter нужно настроить пользователя, под которым будет происходить сбор метрик мониторинга:
CREATE USER postgres_exporter WITH PASSWORD '****';
ALTER USER postgres_exporter SET SEARCH_PATH TO postgres_exporter,pg_catalog;
-- Права доступа для пользователя мониторинга:
GRANT CONNECT ON DATABASE <ваша бд> TO postgres_exporter;
GRANT pg_monitor TO postgres_exporter;Далее необходимо настроить запуск postgres_exporter в виде сервиса.
2. Настройка запуска postgres_exporter в виде сервиса (systemd)
Создаем файл /etc/systemd/system/postgres_exporter.service:
[Unit]
Description=Prometheus PostgreSQL Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=postgres
Group=postgres
Type=simple
ExecStart=/usr/local/bin/postgres_exporter \
--web.listen-address=0.0.0.0:9187 \
--web.telemetry-path=/metrics \
--log.level=info \
--extend.query-path=/etc/postgres_exporter/queries.yaml \
DATA_SOURCE_NAME="postgresql://postgres_exporter:exporter_password@localhost:5432/postgres?sslmode=disable"
Restart=always
[Install]
WantedBy=multi-user.targetЗапускаем и добавляем в автозагрузку:
systemctl daemon-reload
systemctl start postgres_exporter
systemctl enable postgres_exporterПроверяем доступность метрик по адресу http://<IP_postgres_exporter>:9187/metrics
3. Установка и настройка Prometheus
Далее нам нужно установить Prometheus и добавить наш endpoint exporter'а в его конфигурацию /etc/prometheus/prometheus.yml
global:
scrape_interval: 20s
scrape_configs:
- job_name: 'postgres'
static_configs:
- targets: ['IP_postgres_exporter:9187']Теперь запускаем Prometheus и добавляем его в автозагрузку:
systemctl restart prometheus
systemctl enable prometheusЧтобы проверить, что метрики собираются, нужно зайти по адресу http://<IP_prometheus>:9090
4. Установка Grafana и подключение Prometheus как источника данных
На следующем этапе требуется установить Grafana и подключить наш Prometheus как источник данных. Для этого заходим в Grafana: http://<IP\_grafana>:3000, открываем раздел Configuration → Data sources → Add data source → Prometheus, и указываем URL нашего Prometheus — http://<IP_prometheus>:9090
5. Добавление в Grafana готовых дашбордов PostgreSQL
Есть готовые проверенные дашборды, лучше всего будет не изобретать велосипед и воспользоваться ими:
- Postgres Overview https://grafana.com/grafana/dashboards/455-postgres-overview/
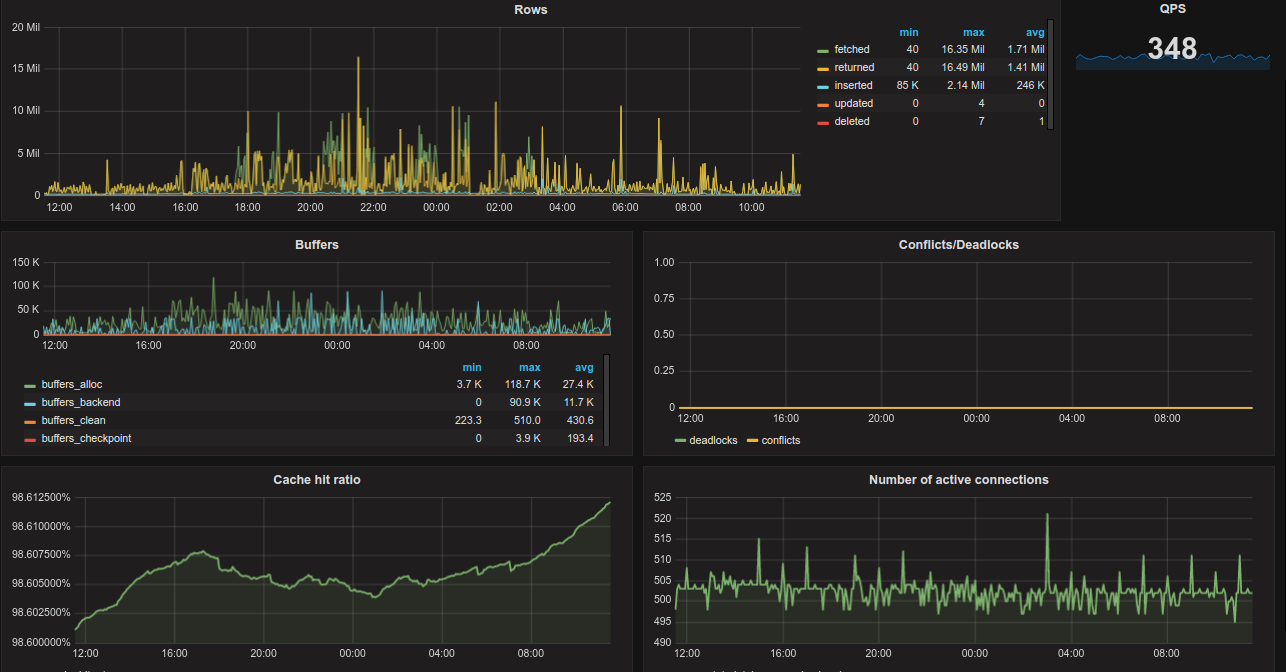
- PostgreSQL Database https://grafana.com/grafana/dashboards/9628-postgresql-database/
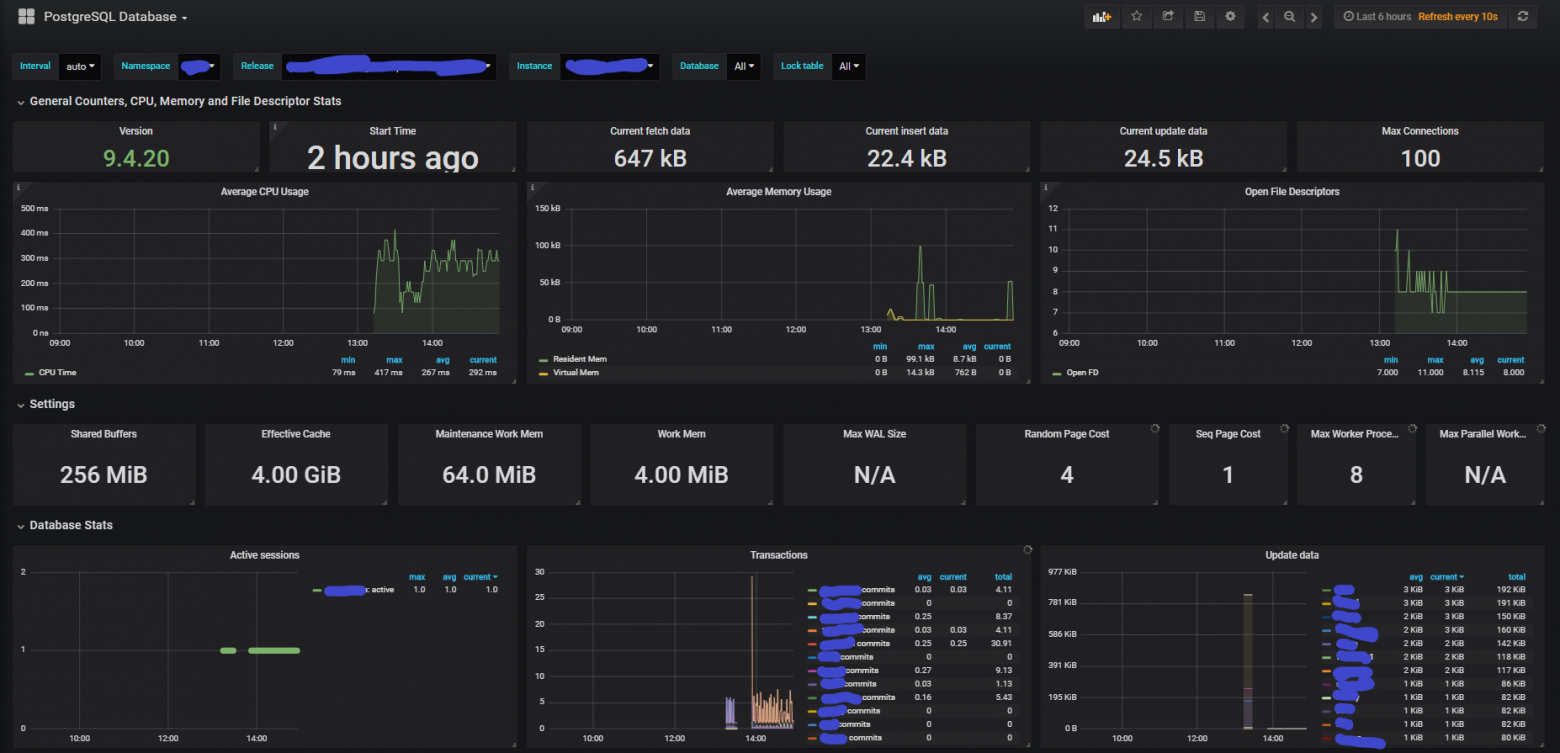
Выбираем понравившийся и далее в Grafana выбираем: Dashboards → Import → вставь ID (9628 или 455) → выбери источник Prometheus.
К плюсам такого решения можно отнести:
- Универсальность архитектуры мониторинга для любых ваших систем. Можно подключаться и мониторить практически все ваши системы в единой архитектуре;
- Можно добавлять новые готовые дашборды или создавать свои;
- Все бесплатно;
- Де-факто промышленный стандарт.
Среди минусов:
- Сложность настройки;
- Отсутствует предиктивная аналитика: вы можете оценивать состояние системы только по состоянию "на сейчас";
- Нет никаких средств управления, даже минимальных;
- Нет встроенной аналитики по "тяжелым" запросам и нет профилировщика таких запросов.
То есть данное решение подходит только для базового мониторинга или для DBA, которые отлично знают, как и что следует добавить в стандартные метрики, чтобы собирать то, что нужно.
Еще нужно определить и настроить необходимые для вас триггеры и оповещения (alerting). Сделать это можно в Grafana ("Alert" → "Create alert rule"), указав запрос метрики, например:
avg(pg_stat_database_blks_hit / (pg_stat_database_blks_hit + pg_stat_database_blks_read))Далее потребуется задать пороговое значение, длительность выдерживания условия, список получателей по email, Slack и т.д.
Также alerting можно настраивать и в Prometheus, однако визуально там сделать это не получится, придется прописывать все алерты в yaml-файлике и подключать ссылку на него в prometheus.yml. В общем, чтобы настроить все "по красоте", понадобится потратить довольно много времени и сил.
Готовые решения open-source
Кто не готов разбираться, настраивать все самостоятельно, и получить на выходе достаточно скудный функционал, могут попробовать open-source решения, разработанные именно для мониторинга PostgreSQL. Рассмотрим два самых популярных из них.
Percona Monitoring and Management (PMM)
Довольно продвинутое решение для мониторинга PostgreSQL (а еще MySQL и MongoDB) с базовыми возможностями аналитики запросов, готовыми дашбордами, рекомендациями и аннотациями. Подходит для production-сред с потребностью в централизованном мониторинге и диагностике.
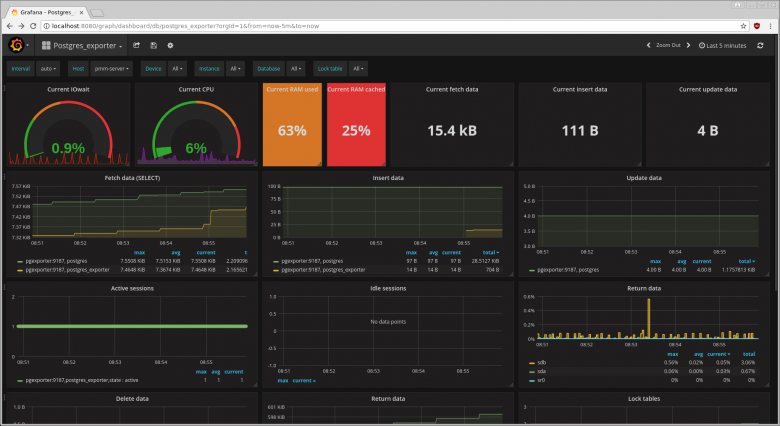
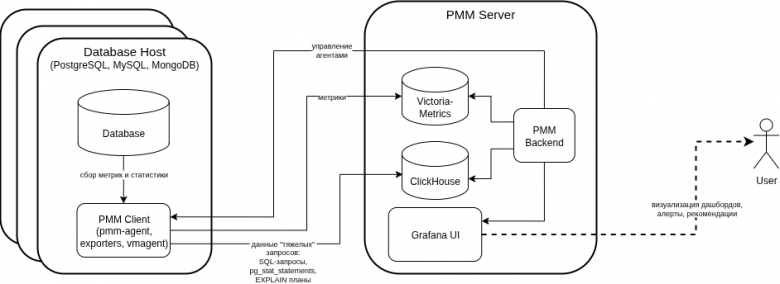
С точки зрения архитектуры здесь используется клиент‑серверная модель:
- PMM Client (устанавливается на каждом сервере с базой данных), включает pmm-agent (управляет процессами), экспортеры (например те самые postgres_exporter и node_exporter) для сбора метрик и vmagent для отправки данных;
- PMM Server (центральный сервер мониторинга) хранит метрики в VictoriaMetrics, аналитические данные запросов — в ClickHouse, визуализация и дашборды делаются через Grafana с разработанными Percona шаблонами для нее (да-да, они как веб-интерфейс используют ту же Grafana). PMM Server включает базовые возможности аналитики тяжелых запросов (т.н. Query Analytics) и Percona Advisors (рекомендации по производительности и безопасности).
Какие возможности здесь предлагаются:
Что имеем здесь с точки зрения плюсов:
- готовые расширенные дашборды для PostgreSQL "из коробки";
- Query Analytics и Advisors (то, чего нет в типовой связке Grafana + Prometheus);
- масштабируемая архитектура;
- гибкость установки через Docker, Helm и пр.
Среди минусов:
- Больше компонентов, т.е. в целом сложнее мейнтейнить;
- Менее универсально — только для трех разновидностей СУБД;
- Сложнее будет "докрутить" своими метриками по сравнению со связкой Prometheus + Grafana.
pgAdmin 4
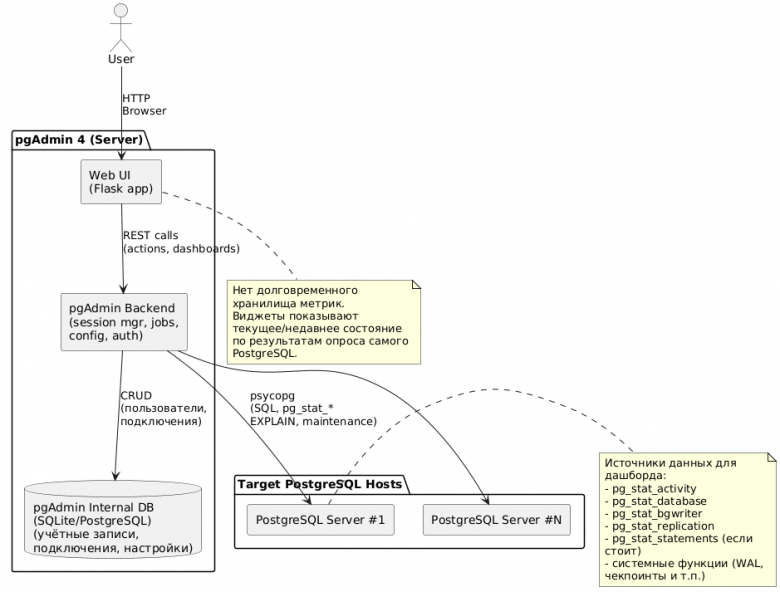
Это не совсем система мониторинга и анализа, скорее, веб-GUI для администрирования PostgreSQL (создание объектов, миграции, бэкапы, Query Tool), в котором есть базовые дашборды по состоянию сервера. Он подходит как удобная админка и точечный мониторинг «здесь-и-сейчас», но не является полноценной системой мониторинга/алертинга.
Архитектура pgAdmin4 — Python (Flask) + psycopg. Работает инструмент в двух режимах: desktop-приложение и сервер (веб-приложение). Данные для виджетов берутся "на лету" из стандартных pg_stat_* представлений и системных функций PostgreSQL. Метрики не накапливает, только опрашивает и показывает по запросу (on demand).
Возможности:
Плюсы pgAdmin 4:
- Работа без агентов: подключается напрямую к PostgreSQL; достаточно сетевого доступа и ролей;
- Продвинутые админ-функции: Query Tool, EXPLAIN, бэкапы, управление объектами и ролями;
- Простая установка: пакеты для Win/macOS/Linux, Docker-образ, Helm
- Работает как десктоп и как веб-приложение.
Минусы:
- Нет никаких хостовых метрик, т.е. аналитика не полная;
- Это не система мониторинга — нет долговременного хранения метрик/серий, показывается только текущее/недавнее состояние без ретроспективной аналитики;
- Нет алертинга, «предиктивной» аналитики, советников и готовых SLO/alerts;
- Ограниченные дашборды по сравнению с PMM/Grafana; нельзя "докрутить" экспортеры/свои метрики, как в Prometheus.
В целом pgAdmin подходит для малых/средних инсталляций, где нет требований к ретроспективному мониторингу и алертингу, или же можно использовать его как дополнение к PMM/Prometheus-стеку, если вы настроены на "зоопарк".
Платные коммерческие решения
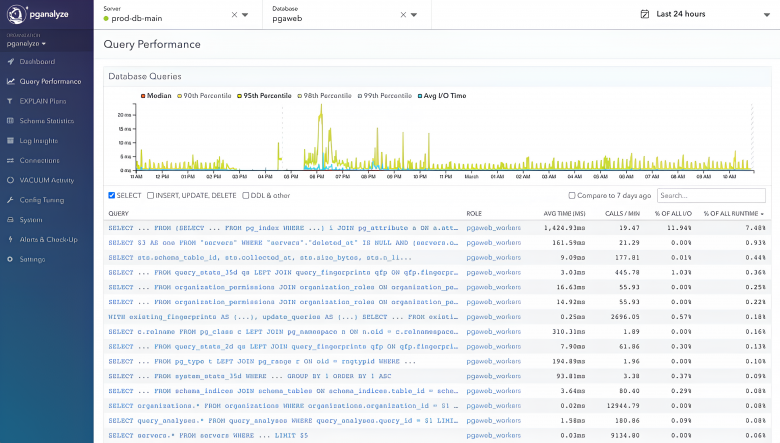
pganalyze
Позволяет проводить достаточно глубокую диагностику и оптимизацию подключенных СУБД. Основная цель — не просто показывать метрики, а автоматически собирать статистику и логи, находить проблемные запросы, давать рекомендации по индексам и обслуживанию (VACUUM/ANALYZE). Есть два варианта поставки:
- SaaS (облачный сервис, в который отправляются данные);
- Enterprise Server (self-hosted) — чтобы "поднять" у себя.
Для сбора метрик используется свой open-source агент (устанавливается рядом с базой и пересылает статистику в pganalyze).
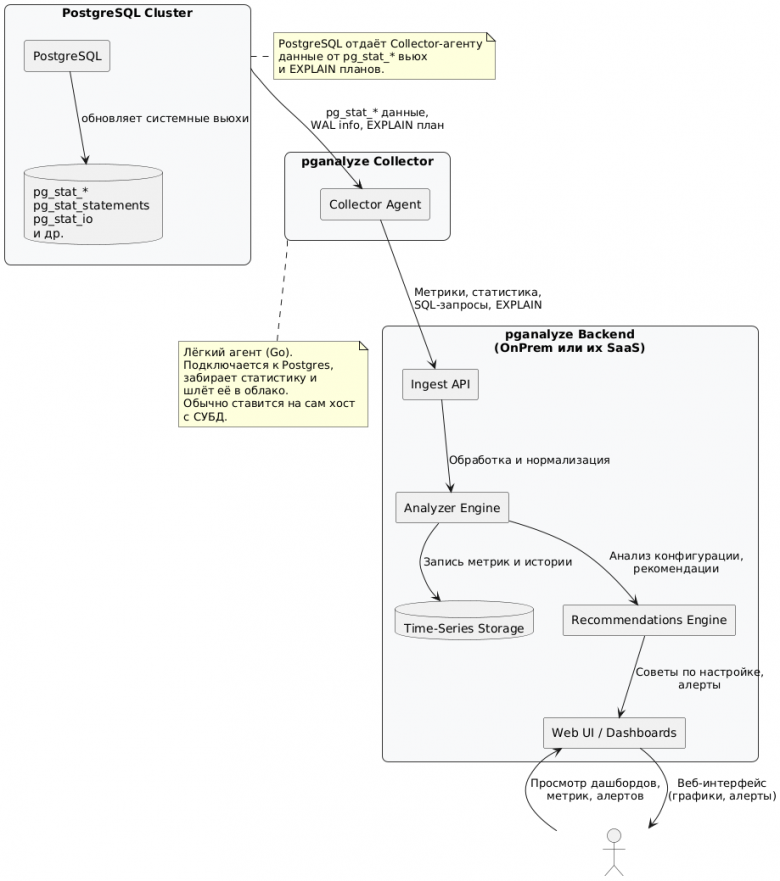
Архитектура pganalyze:
- Collector (open-source агент) — устанавливается на каждом хосте с PostgreSQL и собирает данные из системных views (pg_stat_statements, pg_stat_activity, pg_stat_bgwriter и др.), логов PostgreSQL (парсинг slow queries, ошибок, deadlocks) и настроек конфигурации, затем чере TLS передаёт всё это в сервис pganalyze;
- pganalyze Backend (SaaS или self-hosted) — хранит метрики и логи, анализирует запросы, строит EXPLAIN-планы, выявляет узкие места, генерирует рекомендации: каких индексов не хватает, где нужен VACUUM, где проблема в конфигурации; поддерживает OpenTelemetry для интеграции с APM/Observability-системами;
- Web UI (Dashboard) — доступ через браузер. Есть готовые панели: метрики нагрузки (CPU/IO/locks/sessions), разбивка по запросам и их планам, Index Advisor, Vacuum Advisor, Log Insights (ошибки, deadlocks, медленные запросы). Можно настраивать алерты, например, в Slack.
Возможности:
Что у нас здесь по плюсам:
- Хороший фокус на оптимизацию производительности: автоматические рекомендации по индексам, рекомендации по VACUUM, разбор запросов и логов;
- Collector — open source, легко внедрить и проверить;
- Поддержка как SaaS, так и self-hosted (кому-то может быть удобно в SaaS);
- Богатая встроенная аналитика, которой нет у Prometheus + Grafana.
Минусы:
- Ориентирован только на PostgreSQL (в отличие от Percona PMM, который покрывает ещё MySQL и MongoDB);
- Нет такого широкого комьюнити, как у Grafana/Prometheus;
- Проблемы с приобретением и поддержкой продукта в РФ.
В целом — достаточно продвинутое и богатое решение с массой функционала, которого нет у open-source вариантов.
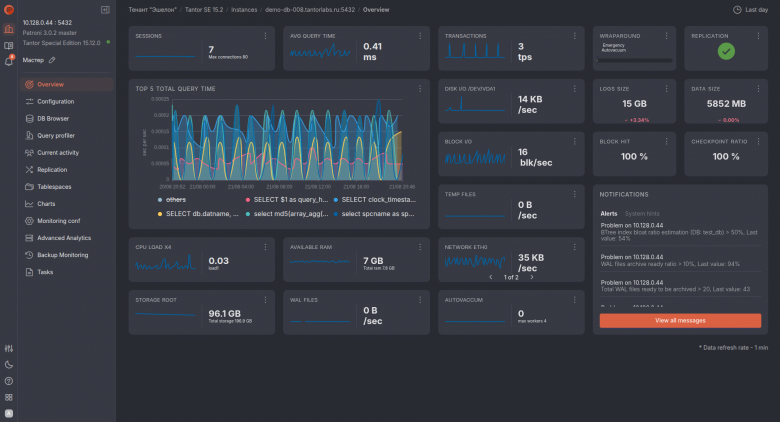
Платформа Tantor
Платформа для мониторинга и аналитики БД на основе PostgreSQL корпоративного уровня. Здесь изначально задана цель не просто отображать метрики, а комплексно управлять всем парком PostgreSQL, собирать и хранить метрики БД и хостов, анализировать запросы и конфигурацию, автоматизировать обслуживание, выдавать рекомендации и централизовать оповещения. Поддерживает мультитенантность (тенанты/воркспейсы), роли и гибкое разграничение доступа. Модель поставки: self-hosted (on-prem), планируется SaaS. Может быть развернута в отказоустойчивом и масштабируемом режиме.
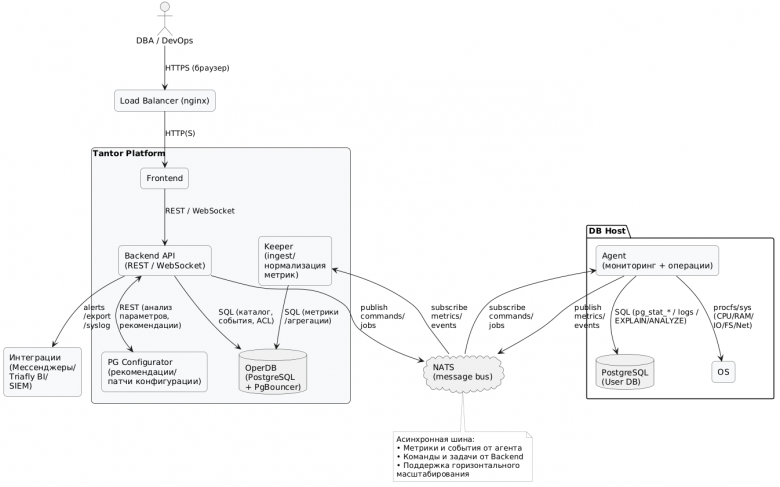
Архитектура платформы Tantor:
- Агенты (на серверах с PostgreSQL). Легковесные go-процессы, которые собирают метрики PostgreSQL из pg_stat_*, pg_stat_statements, событий/логов, сбор pg_store_plans и т.д., снимают хостовые метрики (CPU, RAM, диски, сеть), по командам выполняют операции обслуживания (VACUUM/ANALYZE, скрипты), применяют конфигурации и публикуют изменения метрик в шину сообщений NATS;
- Шина сообщений (NATS). Асинхронный обмен данными: topics/streams: metrics (телеметрия), commands (управляющие задания), events (события), развязка источников/потребителей, буферизация и горизонтальное масштабирование;
- Keeper (ingest/очереди метрик). Принимает и нормализует потоки метрик из NATS, агрегирует и записывает их в хранилище платформы;
- Backend (REST/WebSocket API). Бизнес-логика: каталог инстансов, дашборды, политика доступа, алерты, задания, интеграции. Отдаёт данные UI и управляет агентами (через NATS);
- pg_configurator (advice engine) — сервис рекомендаций по параметрам PostgreSQL, профилям нагрузки, VACUUM/AUTOVACUUM, настройкам памяти и I/O. Возвращает рекомендации и готовые патчи конфигурации;
- OperDB (PostgreSQL, центральное хранилище). Хранит метрики, события, конфигурации, модели воркспейсов/ролей, историю рекомендаций и выполненных задач. Доступ — через PgBouncer;
- Web UI (SPA) — панели мониторинга, профили запросов, журнал событий, конструктор алертов, каталог БД, работа с воркспейсами/пользователями и пр.
- Интеграции. Мессенджеры (Telegram, Mattermost, e-mail): доставка алертов/уведомлений; Triafly BI: экспорт исторических данных мониторинга для долговременной аналитики и построения произвольной отчетности; SIEM: отправка событий/инцидентов по Syslog (внешние SOC/SIEM).
Возможности:
Плюсы:
- Есть темная тема, как в Grafana;
- Глубокая специализация именно под PostgreSQL: рекомендации по конфигурации, анализ планов, операции обслуживания и управление кластерами «из коробки»;
- Единый стек: хранение, бизнес-логика и UI интегрированы; нет зависимости от внешних TSDB/Grafana/ClickHouse;
- Полные метрики: БД и ОС через агентов; асинхронная шина NATS дает масштабируемость и устойчивость к сбоям;
- Мультитенантность и RBAC: удобное разделение инфраструктуры по командам/проектам с прозрачным аудитом;
- Интеграции: мессенджеры, Triafly BI (для долгой истории/отчетности), SIEM (syslog) — без «самоделок»;
- Разработчик в РФ, соответственно, поддержка для корпоративных клиентов;
- Встроенный продвинутый анализатор планов запросов Explain от Tensor https://explain.tensor.ru/ с подсказками, что исправлять в "проблемных" запросах или индексах.
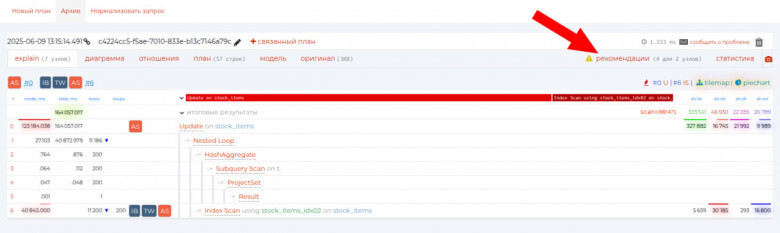
Минусы:
- Только PostgreSQL, но зато любые форки;
- Требует агентов и несколько сервисов: установка/операционка существенно сложнее, чем у простых дашбордов Grafana;
- Кастом-дашбордов нет: ориентирована на встроенные панели;
- Гибкость ниже, чем у чистого Grafana-стека (зато меньше ручной настройки), но реализация кастомных дашбордов есть в планах.
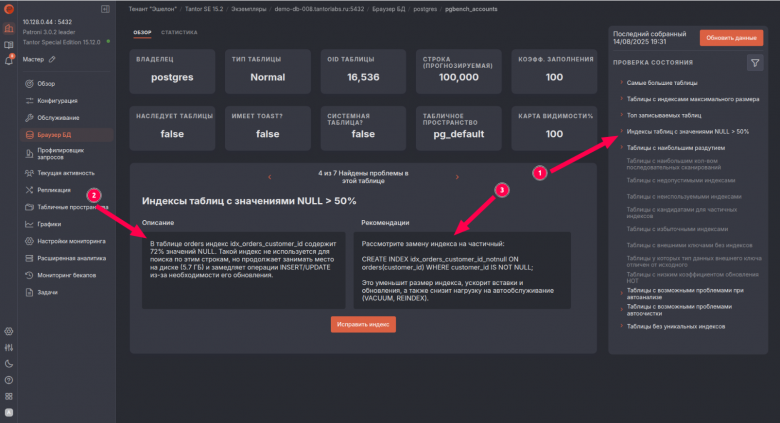
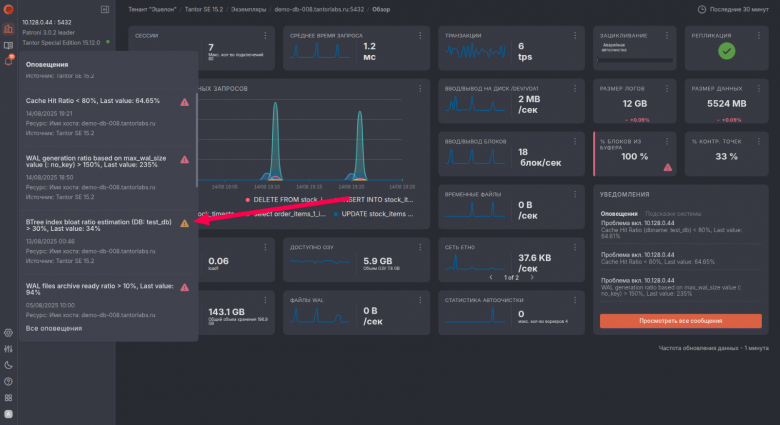
В целом — это платформа уровня enterprise для эксплуатации PostgreSQL: централизует мониторинг, аналитику запросов и управление, снижает TTR за счёт рекомендаций с предиктивной аналитикой и автоматизации, и хорошо вписывается в корпоративный ландшафт через интеграции и роли. Пожалуй, наиболее продвинутое по функционалу решение среди всех.








