Я соглашаюсь с использованием файлов cookie владельцем сайта в соответствии с Политикой обработки файлов cookie tantorlabs.ru и Политикой обработки и защиты персональных данных, в том числе на передачу данных из файлов cookie сторонним статистическим и рекламным службам, указанным в Политике обработки файлов cookie tantorlabs.ru.
Связаться с нами
Отправьте нам ваш вопрос,
и мы обязательно ответим.
- Производительность на уровне мировых лидеров
- Полноценная обработка смешанной нагрузки (HTAP)
- Полная совместимость с бизнес-приложениями, работающими на PostgreSQL (включая «1С»)

В новой МБД Tantor XData Gen3 преодолены фундаментальные ограничения PostgreSQL, реализована архитектура разделения Compute и Storage с использованием технологии RDMA, горизонтальное масштабирование чтения и встроенный пулер соединений.
PostgreSQL без компромиссов:
горизонтальное
масштабирование,
5000+ соединений
и полноценный HTAP
горизонтальное
масштабирование,
5000+ соединений
и полноценный HTAP


Документация
Документация
Сравнение редакций
Сравнение редакций
ВИДЕО: Вадим Яценко, генеральный директор «Тантор Лабс», рассказывает редакции CISOCLUB о Tantor XData Gen3 — новом поколении машин баз данных для самых требовательных информационных систем.
Беседа генерального директора «Тантор Лабс» Вадима Яценко с популяризатором отечественной электроники Максимом Горшениным о новой МБД Tantor XData Gen3
Текстовая версия интервью ➜
- Что за новую архитектуру СУБД реализует третье поколение для высоконагруженных систем?
- Насколько реально сделать настоящий HTAP без потери обратной совместимости с Postgres?
- Подходит ли новая МБД для enterprise и критически важных систем, таких как АБС?
- Может ли она стать альтернативой зарубежным решениям Oracle Exadata, SAP HANA и IBM Netezza?
Текстовая версия интервью ➜
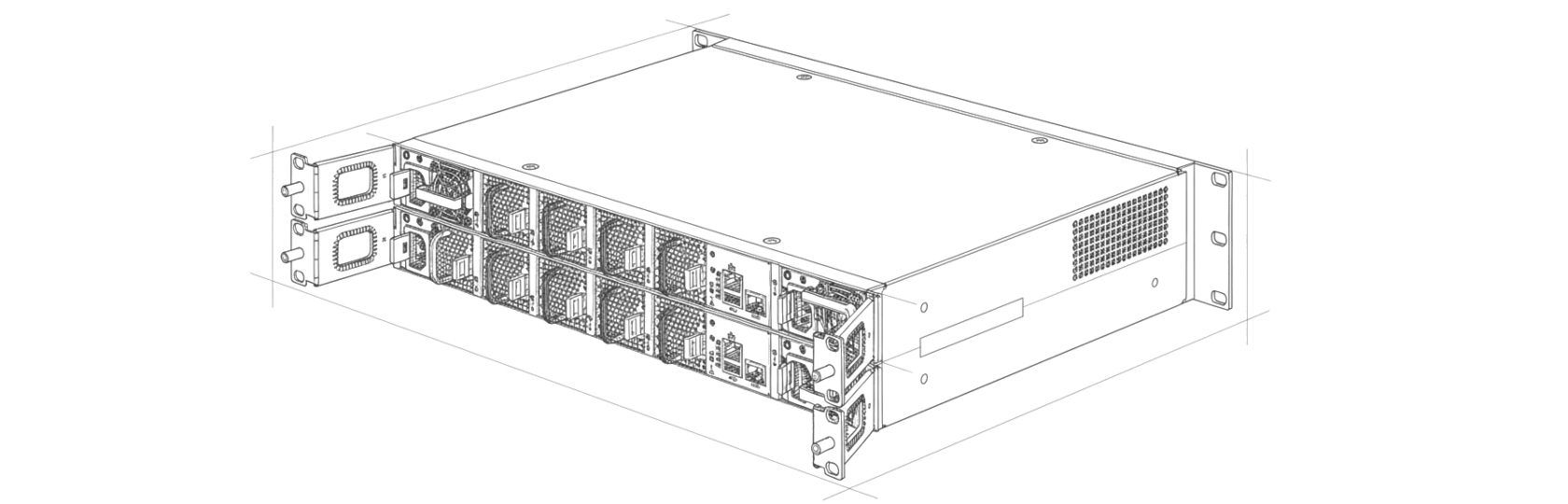
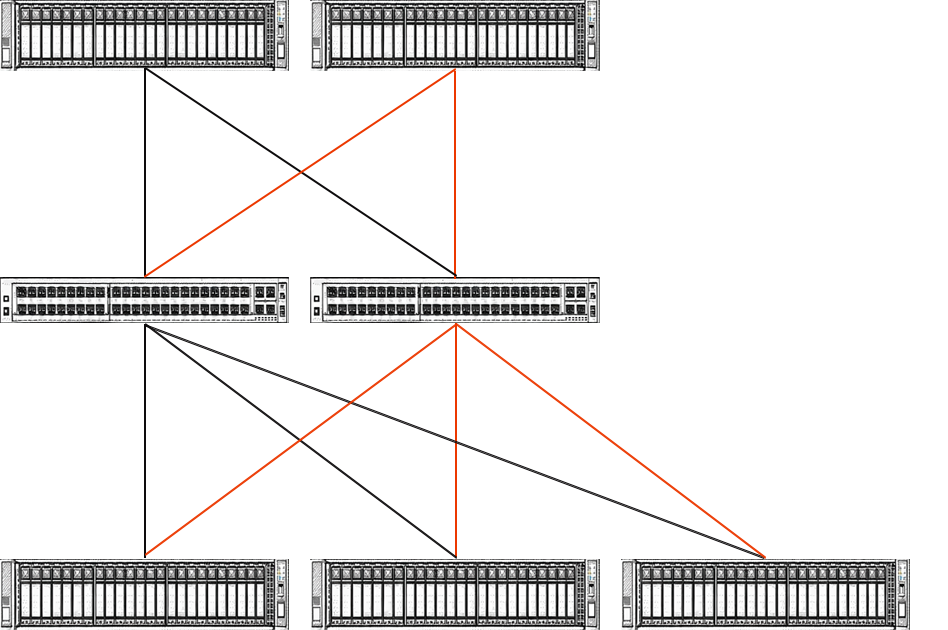
Упрощенная архитектура МБД Tantor XData Gen3 состоит из двух вычислительных узлов, коммутаторов RDMA и трех узлов хранения.
Можно масштабировать отдельно вычислительные узлы и отдельно узлы хранения, снимая проблемы «перекосов» и горизонтального масштабирования. Также могут присутствовать дополнительные узлы управления и прокси в отказоустойчивом режиме.
Можно масштабировать отдельно вычислительные узлы и отдельно узлы хранения, снимая проблемы «перекосов» и горизонтального масштабирования. Также могут присутствовать дополнительные узлы управления и прокси в отказоустойчивом режиме.
Архитектура и основные технологии Tantor XData Gen3
Высокоскоростная сеть RDMA
Критичная технология для архитектуры разделения Compute и Storage
- Сверхбыстрая связь вычислительных узлов с хранилищем и внутренней репликации.
- Протоколы RoCEv2 или InfiniBand — ультранизкие задержки, высокая пропускная способность
- Выделенные каналы 100 Гбит/с для клиентского трафика и синхронной репликации без конфликтов
- Производительность, сопоставимая с локальным SSD, но на общем хранилище
Tantor RAC
(Real Application Clusters)
(Real Application Clusters)
Кластерная технология для отказоустойчивости и балансировки
- Активно-пассивная схема: один пишущий (RW), несколько читающих (RO) узлов
- Автопереключение на реплику с минимальным временем простоя
- Умный прокси с read/write splitting и согласованностью на уровне сессий
- Горизонтальное масштабирование чтения: добавление RO-узлов увеличивает пропускную способность запросов
Tantor PFS – распределенная файловая система
Высокопроизводительный слой хранения, оптимизированный для NVMe и RDMA
- Исключает страничный кэш ОС, позволяя выделить под shared_buffers до 75% RAM
- Предоставляет единое блочное устройство для всех узлов кластера через NVMe-oF
- Сверхнизкие задержки благодаря сети RDMA (InfiniBand / RoCEv2)
Compute / Storage Separation
Независимое масштабирование вычислений и хранения
- Все узлы работают с единым общим хранилищем без дублирования данных на репликах
- Быстрое добавление вычислительных мощностей под растущую нагрузку без миграции данных
- Идеально для сценариев, где «закончился CPU», а место на дисках ещё есть.
Процессоры AMD EPYC™
Максимальная мощность для тяжелых нагрузок
- Большое количество ядер в одном сокете — идеально для MPP и консолидации БД
- Поддержка большого числа линий PCIe 4.0/5.0 — для NVMe и RDMA
- Высокая пропускная способность памяти — до 12 каналов на процессор
- Оптимальное соотношение производительности и энергоэффективности для ЦОД

Решение в МБД Tantor XData Gen3
Классический PostgreSQL и производные форки
Полное разделение Compute и Storage
(Compute-Storage Separation)
(Compute-Storage Separation)
Вычислительные узлы и узлы хранения масштабируются независимо.
Отсутствие горизонтального масштабирования
Ограничен одним физическим сервером. Нельзя добавить мощность при росте нагрузки.
Единое общее хранилище для всех узлов
Реплики (RO-узлы) хранят только мета данные WAL и кэш в памяти, а данные — общие. Это экономит место и упрощает управление.
Избыточность данных и затраты на репликацию
Каждая реплика (Standby) хранит полную копию данных. Для кластера из 3 узлов нужно 3 копии данных.
WAL pipelining (конвейерная обработка WAL)
Выделенные потоки берут на себя запись и сброс WAL, объединяя операции в пакеты. Это резко повышает пропускную способность при большом количестве одновременных транзакций.
Узкие места WAL (write-ahead logging) при высокой нагрузке
При высоком commit rate (частоте фиксации транзакций) все процессы начинают конкурировать за запись в WAL, вызывая сериализацию и падение производи тельности.
Встроенный пулер соединений Shared Server (SS)
Динамически переключает соединения в режим «много клиентов — пул бэкендов», сохраняя состояние сессии в shared memory. По функциональности превосходит PgBouncer.
Деградация при большом количестве соединений (5000+)
Модель «один процесс — одно соединение» приводит к огромным накладным расходам. Тысячи простаивающих соединений «съедают» память и CPU.
CSN (Commit Sequence Number)
Упрощение решений, касающихся видимости транзакций. С CSN это сводится к простому числовому сравнению: транзакция видна, если ее CSN меньше или равен CSN снимка.
Медленное определение видимости строк (MVCC) при высокой конкуренции
В традиционном PostgreSQL MVCC определение видимости транзакции требует проверки ее статуса фиксации в CLOG и сравнения идентификаторов транзакций со списком выполняющихся транзакций, зафиксированных в снимке. С ростом числа соединений это становится узким местом
Massive Parallel Processing (MPP)
на базе Elastic Parallel Query (ePQ)
на базе Elastic Parallel Query (ePQ)
Любой SQL-запрос может выполняться параллельно на всех доступных RO-узлах, которые работают как воркеры. Это превращает СУБД в HTAP-систему.
Слабая параллелизация запросов (Parallel Query)
Параллельное выполнение запроса ограничено одним инстансом (узлом). Нельзя задействовать ресурсы всего кластера для одного аналитического запроса.
Распределенная файловая система PFS поверх NVMe-oF и RDMA
PFS работает в режиме O_DIRECT, полностью исключая страничный кэш ОС. Это позволяет выделять под shared_buffers до 75% RAM и обеспечивает сверхнизкие задержки.
Локальный Storage и зависимость от кэша ОС
Связана с архитектурой, а не с самим PostgreSQL напрямую, но решается на уровне МБД.
Архитектурные проблемы PostgreSQL и их решение в МБД Tantor XData Gen3
Никаких изменений в коде приложений
Кластер «выглядит» как обычный PostgreSQL-сервер. Ничего не нужно дорабатывать. Ваши приложения продолжат работать без изменений, а вы получаете масштабирование и отказоустойчивость уровня иностранных МБД.
Проверенная работа с 1С и другим бизнес-ПО
Благодаря сохранению сессионной модели и полной поддержке транзакций, 1С работает на Tantor XData Gen3 так же, как и на распространенных форках PostgreSQL, но с преимуществами масштабирования.
Поддержка расширений и сессионных объектов
Prepared statements, временные таблицы, курсоры — всё работает благодаря интеллектуальному пулеру Shared Server, который сохраняет состояние сессии (в отличие от PgBouncer).
Возможности экосистемы Tantor
Наиболее функциональная на российском рынке платформа администрирования и мониторинга, многочисленные оптимизации и улучшения.
100% совместимость
с экосистемой PostgreSQL… и даже 1С!
Что такое машина баз данных Tantor XData?
Следующий уровень для тех, кто исчерпал возможности традиционных СУБД и серверов
Если вы уже работаете с базами данных, но сталкиваетесь с замедлением запросов, сложностями масштабирования информационных систем или непредсказуемыми нагрузками, представьте решение, где аппаратная мощность и программная логика объединены в единый оптимизированный программно-аппаратный комплекс (ПАК).
Специализированный продукт, созданный для высоконагруженных систем и растущих потребностей бизнеса
МБД Tantor XData автоматически распределяет ресурсы и обрабатывает большое число запросов и огромные объемы данных — десятки тысяч операций в секунду — за счет глубокой интеграции аппаратного и программного обеспечения. А удобное управление и обслуживание позволяет сосредоточиться на бизнес-задачах и повышении производительности, а не на проблемах инфраструктуры.
Высокая операционная эффективность
МБД Tantor XData рассчитаны на скоростную обработку данных в высоконагруженных системах, позволяют обеспечить заявленную производительность, а также доступность и безопасность highload инфраструктуры. Использование корпоративных машин баз данных Tantor XData в корпоративных ЦОДах или публичных облаках помогает добиться высокой отказоустойчивости и операционной эффективности, снизить нагрузку на администраторов и общую стоимость владения ИТ-ландшафтом.


Для высоконагруженных систем, в которых критически важна скорость, надежность, высокая доступность и масштабируемость
Применение машин баз данных линейки Tantor XData
Телекоммуникации
- Обработка CDR (Call Detail Records) — анализ звонков, тарификация
- Персонализация тарифов — рекомендации на основе Big Data
- Мониторинг сетевой нагрузки – прогнозирование пиковых нагрузок
Розничная торговля и eCommerce
- Рекомендательные системы
- Управление запасами (прогнозирование спроса)
- Анализ покупательского поведения – сегментация клиентов
Финансовый сектор
- Обработка транзакций в реальном времени (платежи, переводы, биржевые операции)
- Антифрод и AML (Anti-Money Laundering) — быстрый анализ больших объемов транзакций
- Кредитный скоринг и риск-аналитика — прогнозирование на основе исторических данных
Госсектор и безопасность
- Мониторинг и аналитика социальных данных
- Кибербезопасность — анализ логов в реальном времени
Промышленность и IoT
- Логистика и управление цепочками поставок
- Предиктивная аналитика (предсказание поломок оборудования)
- Сбор данных с датчиков

Типовые сценарии для применения Tantor XData
- БД для «тяжелых» корпоративных ERP от «1С» при миграции с MS SQL
Высоконагруженные системы «1С:ERP»
- Организации, использующие Exadata для высоконагруженных систем
Замена Oracle Exadata
Дорожная карта МБД Tantor XData Gen3

- МБД Tantor XData Gen3 в исполнении XScale (включение специальной редакции платформы контейнеризации «Боцман» в состав ПАК)
- Возможность автоматического масштабирования узлов кластера в зависимости от нагрузки
- DBaaS on-premise: множество экземпляров СУБД с изоляцией ресурсов
- DBaaS в Астра Облаке: использование изолированных ресурсов с максимальной производительностью
Возможность тестирования сценариев заказчика с 1 апреля в ЦОД XData
Релиз МБД Tantor XData Gen3. В составе — специальная редакция Tantor Polar.
Исполнение bare-metal, готовность к самым высоким нагрузкам (OLTP, OLAP, HTAP)
Исполнение bare-metal, готовность к самым высоким нагрузкам (OLTP, OLAP, HTAP)
Q3
Q2
Q1
- Регистрация ПАК Tantor XData Gen3 в реестре Минпромторга
Q4
Обратная связь
Отправьте нам ваш вопрос или предложение, и мы обязательно ответим.
Новости по Tantor XData