
При нагрузочном тестировании баз данных Tantor Postgres или других на базе PostgreSQL с использованием стандартного инструмента pgbench отсутствие фиксации деталей окружения (таких как конфигурация СУБД, характеристики сервера, версии ПО) часто приводит к нерепрезентативным результатам и необходимости повторных тестов. В статье рассматривается разработанный автором инструмент pg_perfbench, который призван решить эту проблему.
Инструмент автоматизирует запуск pgbench с генерацией TPC-B-нагрузки, собирает полные метаданные о среде тестирования и формирует структурированный отчет, обеспечивая воспроизводимость сценариев, исключая утерю критической информации и упрощая сравнение результатов за счет фиксации всех параметров в едином шаблоне.
Рассматриваемый проект находится в репозитории https://github.com/TantorLabs/pg_perfbench
Автоматизация нагрузочного тестирования БД на базе PostgreSQL и сбора системной информации
Для проверки гипотез или общей производительности БД Tantor Postgres или других на базе PostgreSQL в ходе разработки и сопровождения часто возникает необходимость быстро провести нагрузочный тест. Чаще всего для генерации TPC-B нагрузки специалисты используют стандартный инструмент pgbench и оценивают результаты, однако при описании итогов таких тестов нередко упускаются важные детали окружения. Отсутствие четкого описания используемой конфигурации: параметров PostgreSQL, аппаратных характеристик сервера, версии клиента и настроек сети — может приводить к неоднозначным или неполным выводам о производительности. Это может приводить к необходимости тратить время на повторный прогон тестов.
Чтобы исключить подобную рутину и минимизировать риск «забытых» деталей, я разработала инструмент pg_perfbench, который запускает pgbench и собирает сведения об окружении БД, после чего генерирует полный отчет по заранее заданному шаблону. Это помогает воспроизводить сценарии тестирования, фиксировать все необходимые детали окружения БД и при необходимости быстро сравнивать результаты тестов.
Предпосылки к разработке
Рассмотрим типовой сценарий измерения производительности Tantor Postgres или других БД на базе PostgreSQL, в ходе которого необходимо не только получить цифры по транзакциям в секунду, но и составить детальное описание проведенного тестирования. В реальной практике администраторы и разработчики БД сталкиваются с такими задачами:
- Проверить поведение БД при увеличении нагрузки (числа соединений, размера данных и т. д.).
- Сравнить производительность разных версий PostgreSQL или разных конфигураций (например, различные параметры shared_buffers, work_mem, включенные расширения и т.д.).
- Зафиксировать результаты тестов для последующего анализа и воспроизведения.
Однако без полного описания окружения, включая версии ПО, параметры сетевой инфраструктуры, характеристики сервера (CPU, RAM, дисковая подсистема) и саму конфигурацию PostgreSQL, дальнейший анализ и воспроизведение экспериментов становятся довольно затруднительными. Любое неучтенное изменение, будь то использование разных дата-директорий (например, одна с включенными checksums, а другая — без них) или иные отличия аппаратной и сетевой конфигурации, способно существенно повлиять на результаты. Тогда при попытке сопоставить новые показатели с предыдущими выясняется, что тесты фактически несопоставимы, поскольку проходили в различных условиях.
Именно из потребности в фиксировании как показателей производительности, так и деталей окружения, возникла идея дополнить стандартные инструменты нагрузочного тестирования автоматической генерацией отчетов. Для однотипных прогонов pgbench хорошо подходят решения с кастомными скриптами, но они часто требуют доработки и вручную собранных данных для формирования полноценной картины. На практике это ведет к росту временных затрат и риску упустить в итоговом описании какую-то важную деталь.
Стандартный цикл нагрузочного тестирования с pgbench
pgbench оперирует нагрузкой, построенной по модели TPC-B, и позволяет быстро получить следующие метрики:
- tps (transactions per second) – количество транзакций, выполненных за секунду.
- Latency average – среднее время задержки между выполнением транзакций, измеряется в миллисекундах (мс).
- Number of transactions actually processed – общее количество успешно обработанных транзакций.
- Number of failed transactions – количество транзакций, завершившихся с ошибкой.
- Initial connection time – время, затраченное на установление первоначального соединения с базой данных, измеряется в миллисекундах (мс) или секундах (c) в зависимости от контекста измерения.
Для иллюстрации возьмем классический сценарий: циклический запуск pgbench в простом Bash-скрипте с итерациями, где варьируется количество клиентов (соединений с БД). Пример подобного скрипта:
/usr/lib/postgresql/15/bin/pgbench -i --scale=4000 --foreign-keys -h `hostname` -p 5432 -U postgres test
#!/bin/bash
clients="1 10 20 50 100"
t=600
dir=/var/lib/postgresql/test_result
mkdir -p $dir
for c in $clients; do
echo "pgbench_${c}_${t}.txt"
echo "start test: "`date +"%Y.%m.%d_%H:%M:%S"` >> "${dir}/pgbench_${c}.txt"
/usr/lib/postgresql/15/bin/pgbench -h `hostname` -p 5432 test -c $c -j $c -T $t >> "${dir}/pgbench_${c}.txt"
echo "stop test: "`date +"%Y.%m.%d_%H:%M:%S"` >> "${dir}/pgbench_${c}.txt"
doneДанный код:
- Инициализирует тестовую базу pgbench с масштабом 4000 (параметр --scale=4000) и внешними ключами (--foreign-keys).
- Запускает циклы нагрузок по переменному числу клиентов (1, 10, 20, 50, 100) в течение 600 секунд (-T 600).
- Логирует результаты в отдельные файлы, начиная и завершая каждую итерацию отметками времени.
На выходе обычно формируют график, отражающий зависимость показателей (например, tps или средней задержки) от числа клиентов:
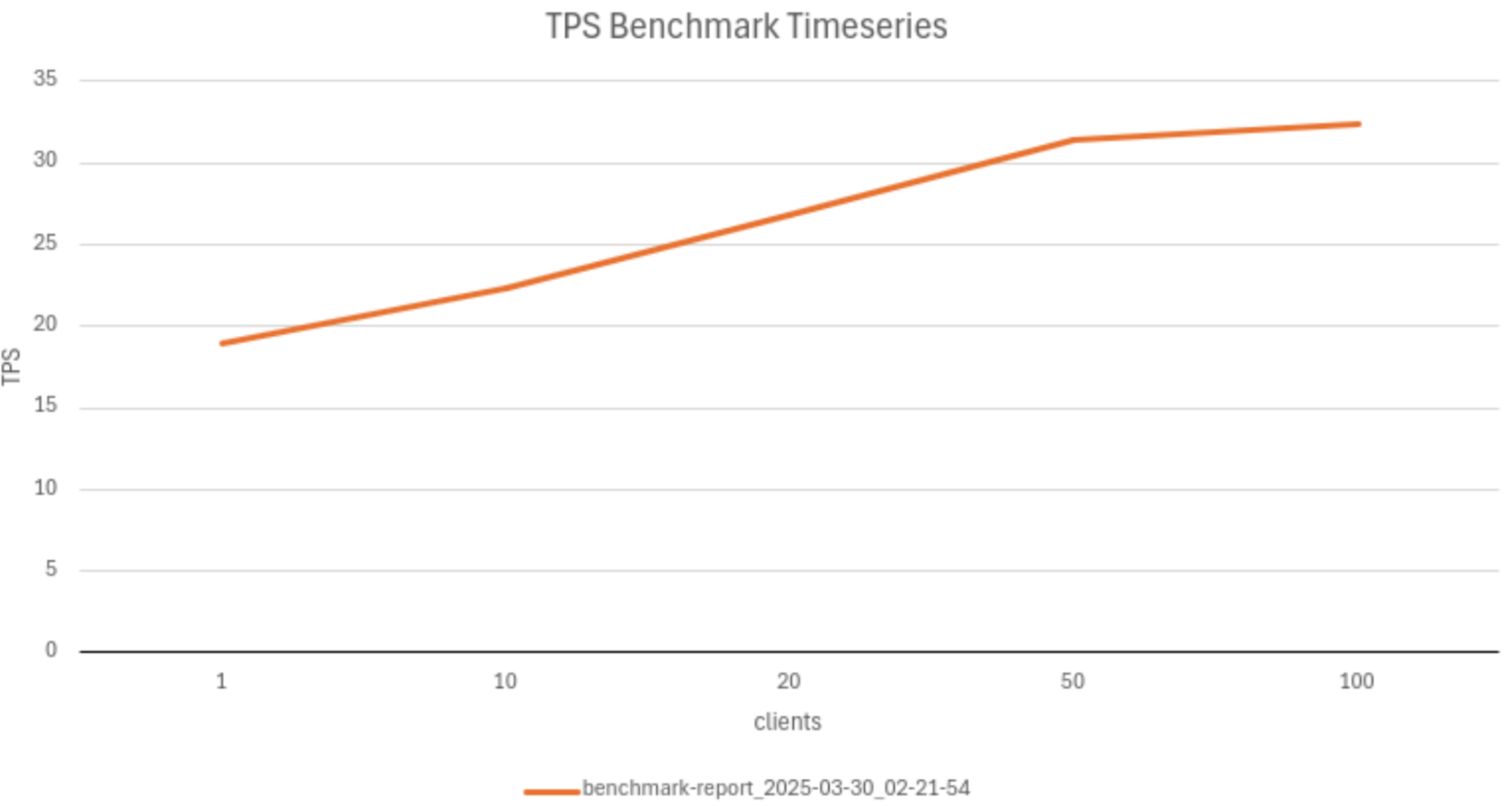
Также можно сделать дополнительный график для отображения задержки Latency average.
Несмотря на то что данные pgbench уже дают базовую оценку производительности, полноценный анализ также требует учета:
Серверные параметры:
Параметры БД:
- CPU (модель, количество ядер, поддержка Hyper-Threading);
- RAM (объем, частота, тип);
- disk space (тип носителя, объем, конфигурация RAID и т. д.);
- настройки сетевых параметров (TCP/IP stack, MTU и т. п.).
- системные драйверы (например, для SSD или сетевых карт).
Параметры БД:
- точная версия PostgreSQL (сервер и клиент, при необходимости — патчи);
- включенные расширения (например, pg_repack, pg_stat_statements);
- конфигурация БД (postgresql.conf) и важнейшие параметры (shared_buffers, work_mem, wal_buffers и т. д.);
- результаты pg_config (опции сборки, путь к каталогам и т. д.);
- включенные репликации (физическая или логическая).
При повторном воспроизведении того же теста необходимо соответствие вышеописанных параметров окружения, ведь несовпадения в перечисленных аспектах могут повлиять на итоговые цифры (к примеру, если CPU в одной среде отличается от CPU в другой, то прямое сравнение результатов tps становится бессмысленным). Поэтому при серьезных исследованиях необходимо подтверждать, что тест был воспроизведен с теми же параметрами окружения.
Необходимость готовых решений и автоматизации
Для проведения нагрузочного тестирования и сбора перечисленной системной информации можно воспользоваться набором опенсорсных утилит, но практически все они требуют ручной интеграции и дополнительных скриптов. Другими словами, администратору приходится отдельно собирать информацию о конфигурации Tantor Postgres или другой БД на базе PostgreSQL, сетевых настройках, версии ядра операционной системы и т. п., а уже затем формировать единый отчет, причем чаще всего это происходит в произвольном формате, что вызывает сложности при сопоставлении с отчетами коллег.
Таким образом, чтобы все необходимые детали собирались и документировались автоматически, нужна дополнительная надстройка над стандартными инструментами. Именно этой задаче pg_perfbench и призван помочь, ведь он позволяет:
- запускать типовые или кастомные сценарии pgbench;
- параллельно собирает метаданные о железе, ОС и настройках PostgreSQL;
- автоматически формировать итоговый отчет по заданному шаблону.
В результате при проведении нагрузочных тестов можно быть уверенным, что никакая критически важная деталь, касающаяся окружения, не ускользнет из виду. Такой отчет упрощает сопоставление результатов, экономит время на конфигурацию повторных прогонов и обеспечивает высокую степень воспроизводимости экспериментов.
Автоматизация исследования производительности БД
Общая схема работы pg_perfbench при выполнении нагрузочного тестирования:
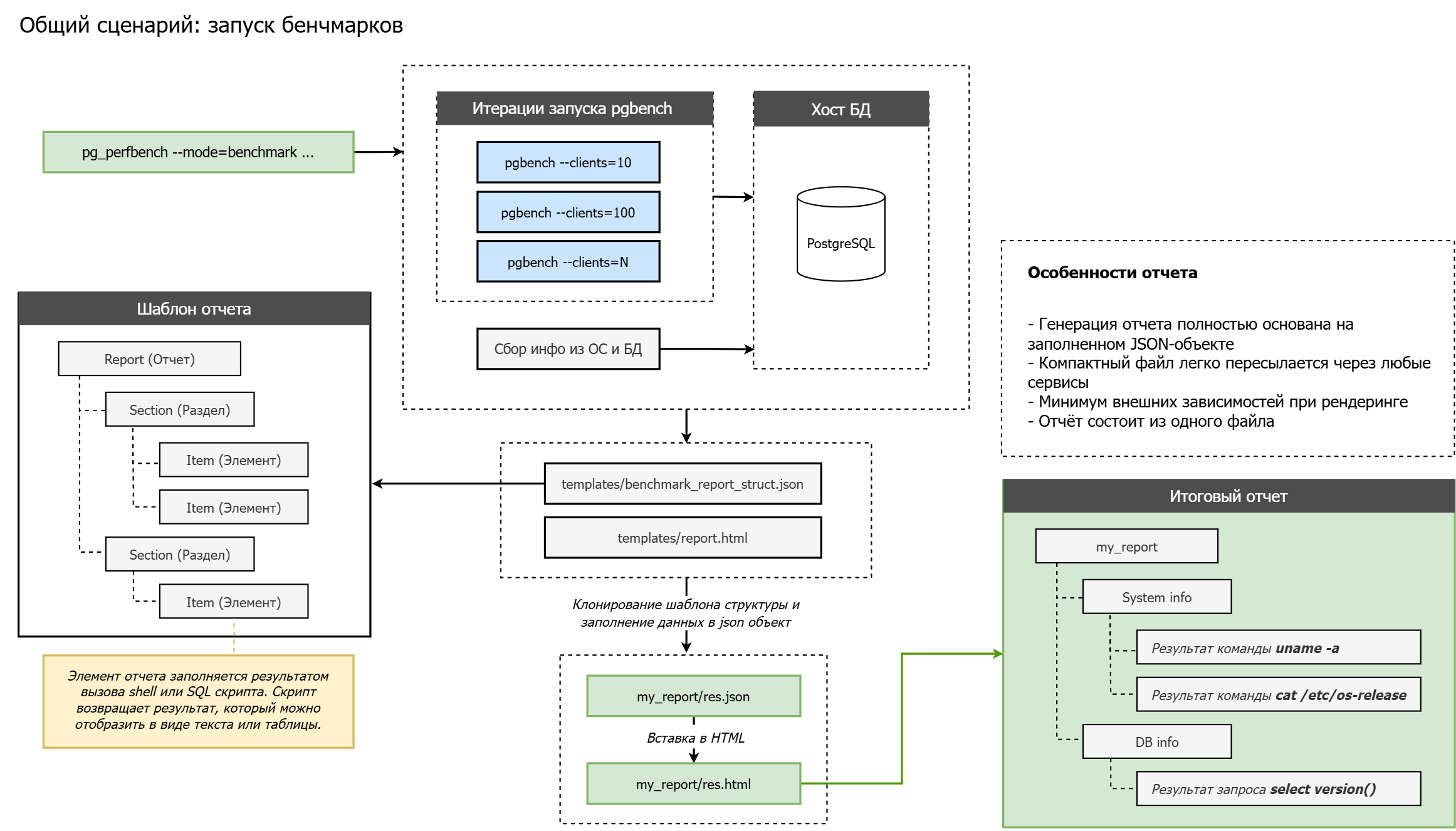
Процесс нагрузочного тестирования и анализа производительности PostgreSQL значительно упрощается, если в итоге мы получаем полноценный структурированный отчет, содержащий не только числовые показатели (tps, Latency average и пр.), но и детальную информацию об окружении. Такой отчет помогает:
Сформированный отчёт содержит несколько основных секций:
Свернутые разделы отчета:
- Сопоставлять результаты различных прогонов и версий конфигурации без потери контекста.
- Хранить всю необходимую информацию о сервере, параметрах PostgreSQL и сетевых настройках в одном месте.
- Воспроизводить тестовые сценарии, имея под рукой готовый шаблон с нужными данными.
Сформированный отчёт содержит несколько основных секций:
- System properties — описывает характеристики аппаратной части (процессор, память, диски, сетевые настройки).
- Common database info — содержит информацию о версии PostgreSQL, подключённых расширениях и ключевых параметрах БД.
- Common benchmark info — указывает параметры запуска pgbench (количество клиентов, время тестирования, используемые команды).
- Tests result info — подводит итоги выполненных тестов, отображает показатели производительности (TPS, задержки и пр.).
Свернутые разделы отчета:
Для формирования отчетов выбраны форматы, позволяющие легко читать и визуализировать результаты тестирования: JSON для хранения данных (включая результаты замеров и конфигурацию) и HTML для наглядного отображения отчета с возможностью добавить ссылки, стили, графики и т. п. В нашей реализации HTML-отчет содержит вложенный JSON-объект с наполненными данными, на основе которого происходит визуализация этого отчета. Таким образом, итоговый процесс может выглядеть как:
- Запуск тестовых сценариев и сбор информации.
- Автоматическое формирование отчета: создается JSON-файл с детализированной структурой и разделами, а также генерируется HTML-версия отчета по тому же шаблону.
- Анализ результатов: из JSON берутся необходимые значения для построения графиков, таблиц сравнения и т. д., а HTML-отчет визуализирует результаты тестирования в удобном интерактивном виде.
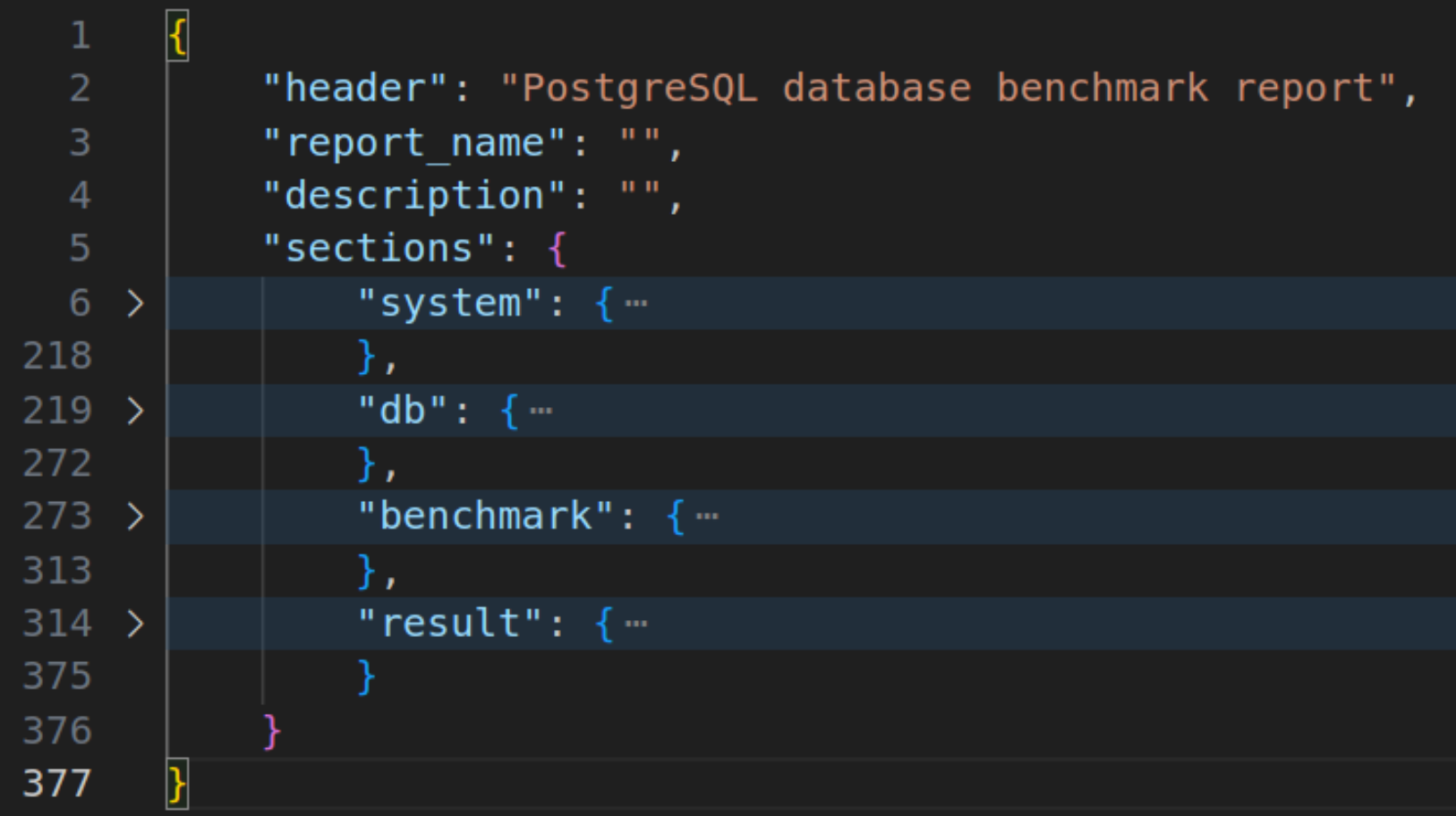
Каждый раздел имеет параметры для разметки структуры интерактивного HTML-отчета:
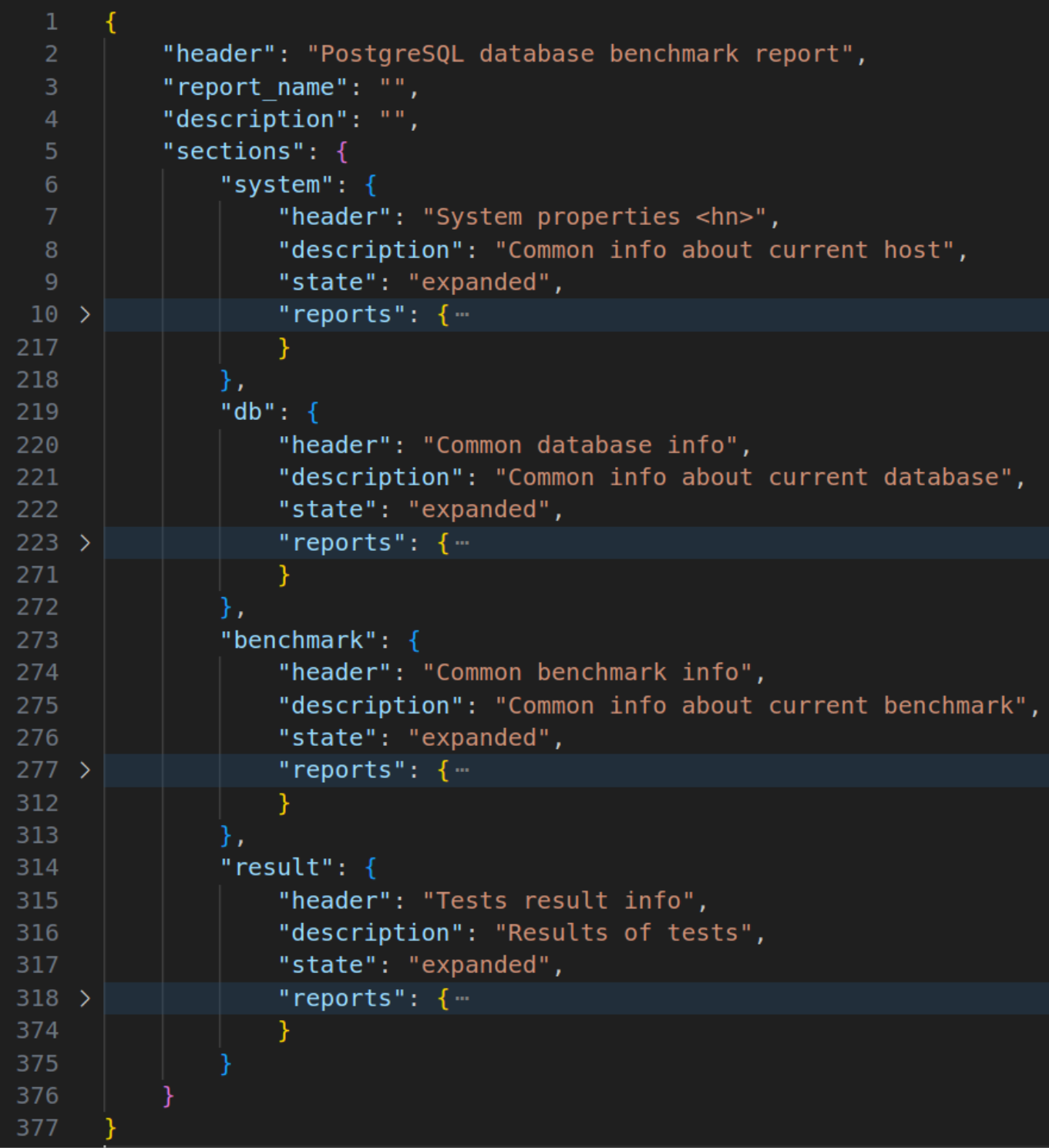
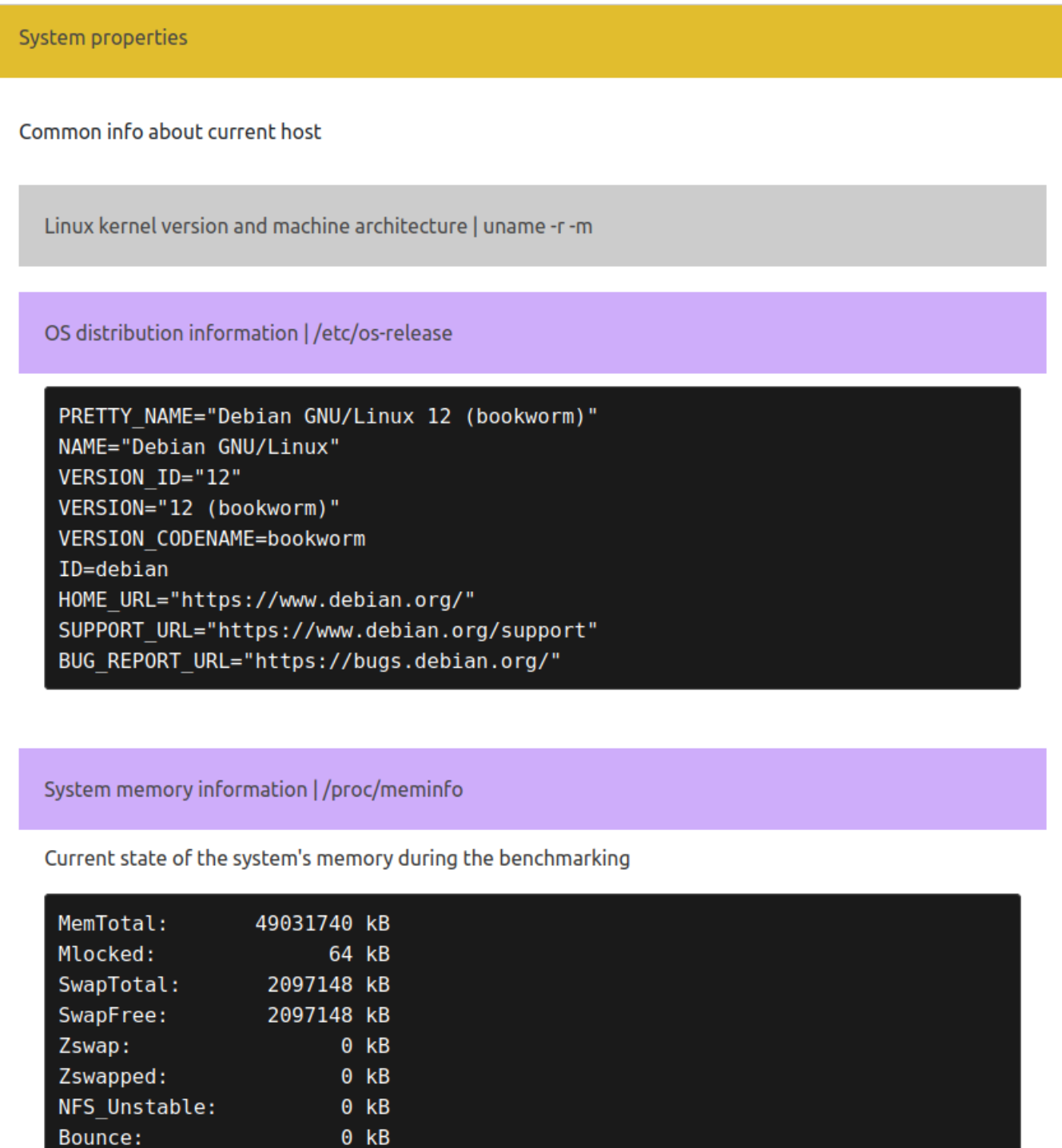
Раздел с описанием серверного окружения может включать таблицу с информацией о процессоре, памяти, дисках, а также вывод некоторых системных команд. Развернутый раздел содержит элементы(в свернутом состоянии):

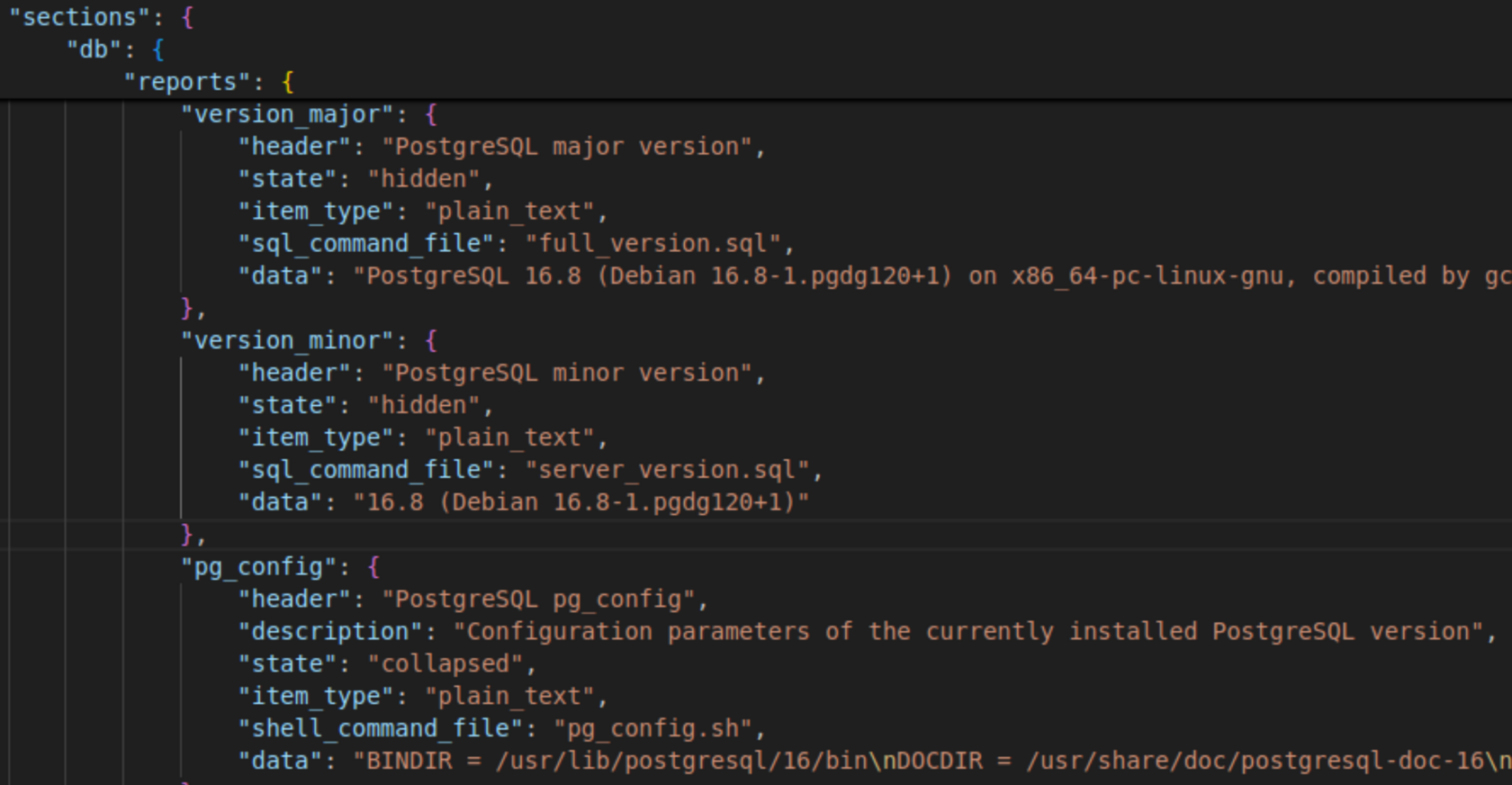
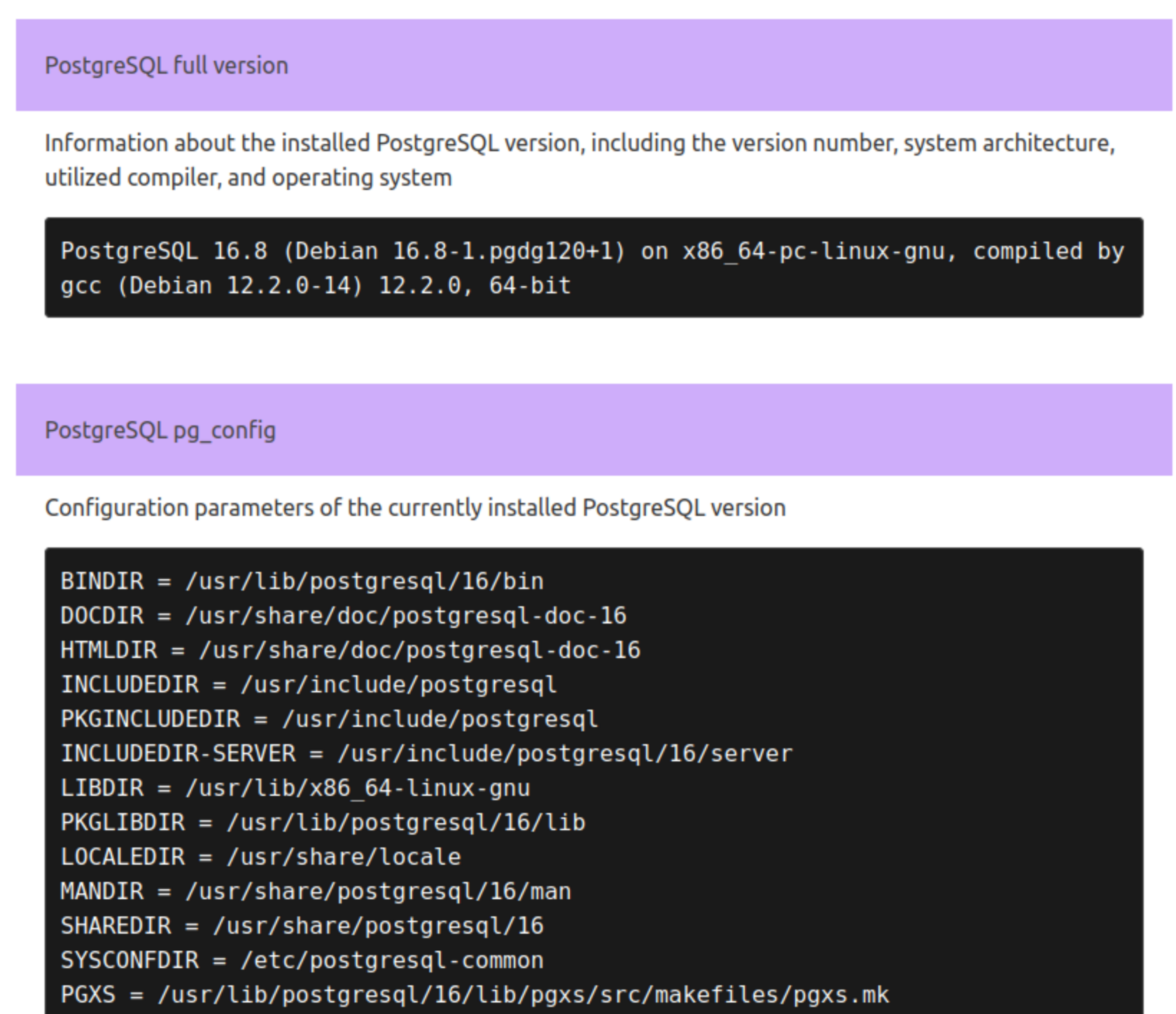
Раздел с описанием конфигурации БД может содержать параметры postgresql.conf, список расширений и т. д.:
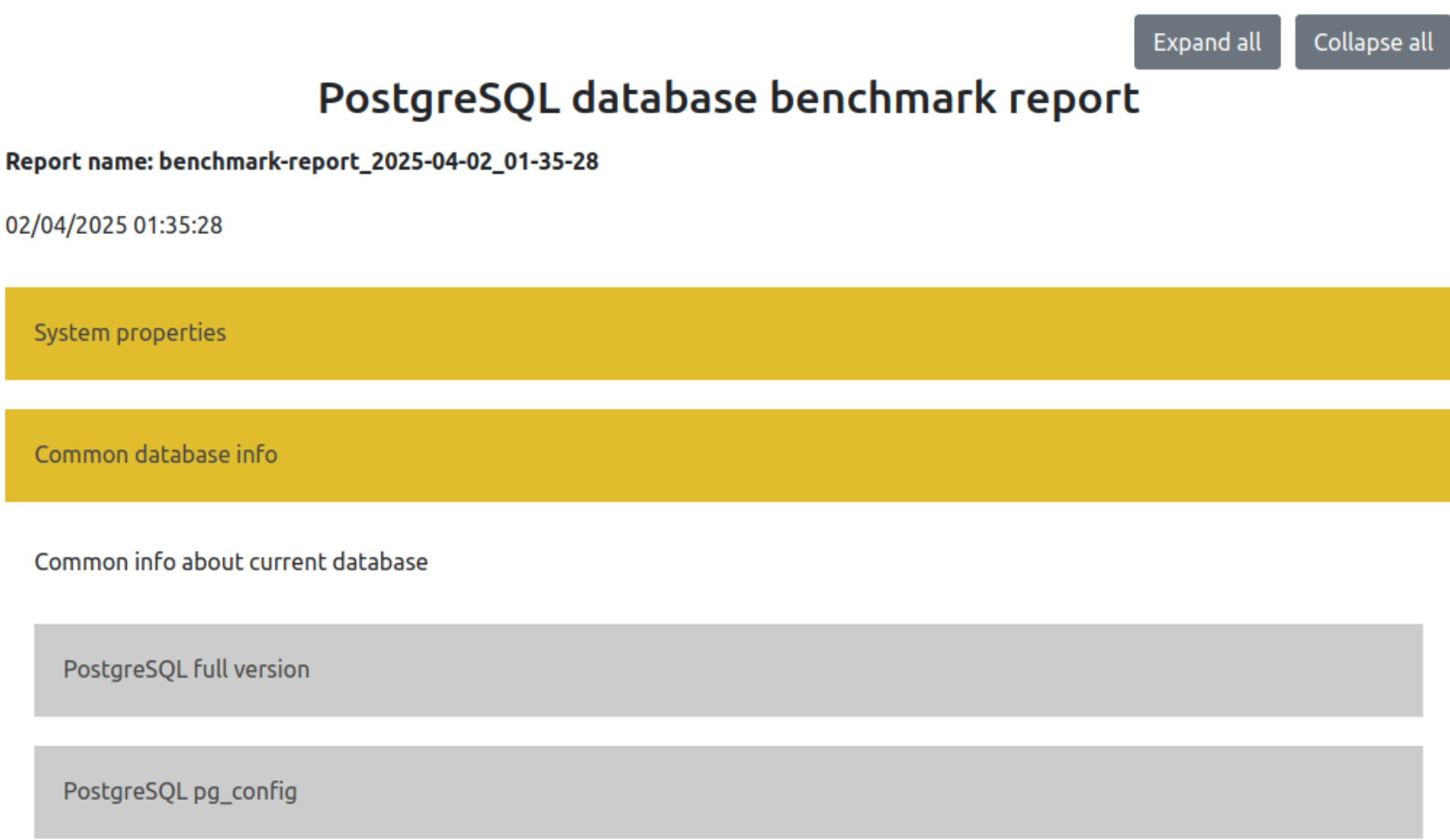
Сбор информации об окружении БД
Для сбора серверной информации обычно выполняются команды в терминале, например:
df -h # <---- дисковое пространство
cat /etc/fstab # <---- описание файловых систем
cat /etc/os-release # <---- описание дистрибутива Linux
uname -r -m # <---- версия ядраДля сбора информации об окружении БД можно использовать shell-команды или SQL-команды, которые находятся в отдельных файлах. В описании элемента отчета указывается файл с этими командами, а их результаты включаются в поле data:
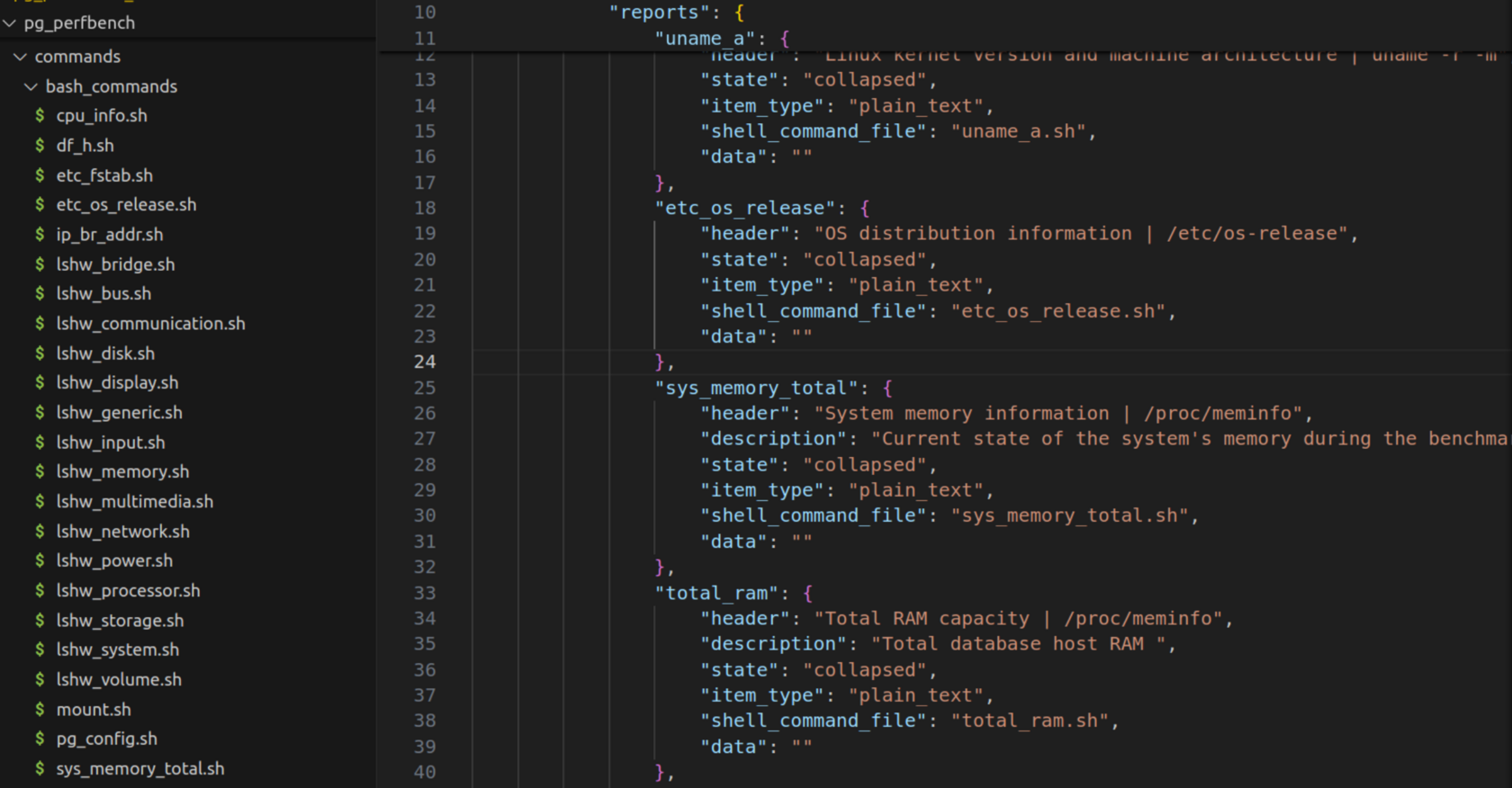
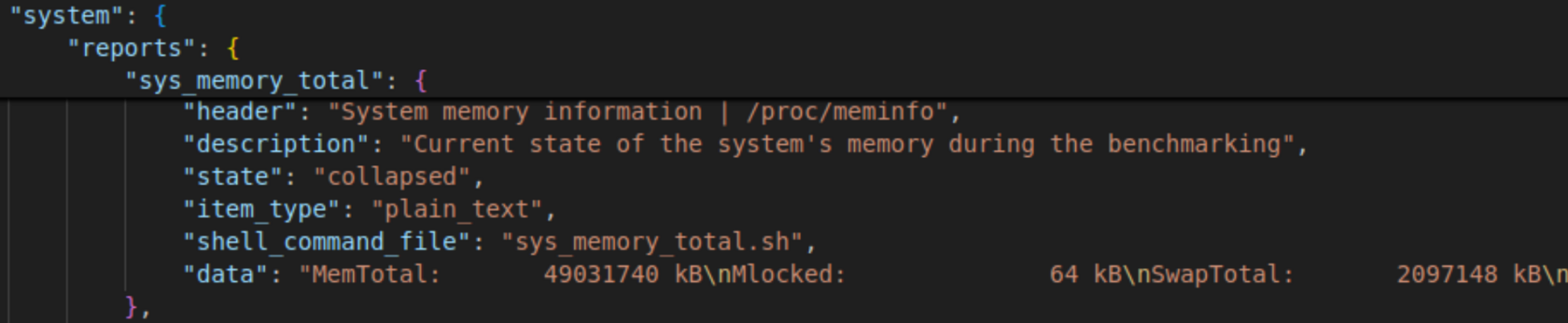
Посмотрим на раздел отчета с заполненными данными о серверном окружении:
Каждый элемент отчета структуры имеет описание для интерактивной разметки в HTML, который включает параметры:
- header – указываемое имя раздела;
- description – описание или краткое пояснение;
- state – состояние элемента отчета(свернутый или развернутый);
- item_type – тип возвращаемого результата скрипта(таблица или текст);
- shell_comand_file или sql_command_file – название shell или SQL скрипта;
- data – поле, куда записывается результат выполнения скрипта.
Аналогичным образом устроен сбор информации из БД:
Конфигурация нагрузочного тестирования БД
Конфигурация параметров pgbench происходит в пользовательских параметрах pg_perfbench:
python -m pg_perfbench --mode=benchmark \
--log-level=debug \
--connection-type=ssh \
--ssh-port=22 \
--ssh-key=/key/p_key \
--ssh-host=10.100.100.100 \
--remote-pg-host=127.0.0.1 \
--remote-pg-port=5432 \
--pg-host=127.0.0.1 \
--pg-port=5439 \
--pg-user=postgres \
--pg-password=pswd \
--pg-database=tdb \
--pg-data-path=/var/lib/postgresql/16/main \
--pg-bin-path=/usr/lib/postgresql/16/bin \
--benchmark-type=default \
--pgbench-clients=1,10,20,50,100 \
--pgbench-path=/usr/bin/pgbench \
--psql-path=/usr/bin/psql \
--init-command="ARG_PGBENCH_PATH -i --scale=10 --foreign-keys -p ARG_PG_PORT -h ARG_PG_HOST -U postgres ARG_PG_DATABASE" \
--workload-command="ARG_PGBENCH_PATH -p ARG_PG_PORT -h ARG_PG_HOST -U ARG_PG_USER ARG_PG_DATABASE -c ARG_PGBENCH_CLIENTS -j 10 -T 10 --no-vacuum"При этом все настройки фиксируются в отчете для комплексного описания запуска инструмента. Количество итераций также задается пользователем: можно задать либо --pgbench-clients (число клиентов), либо --pgbench-time (длительность) каждого тестового прогона.
Конфигурация пользовательских параметров pg_perfbench описана в документации.
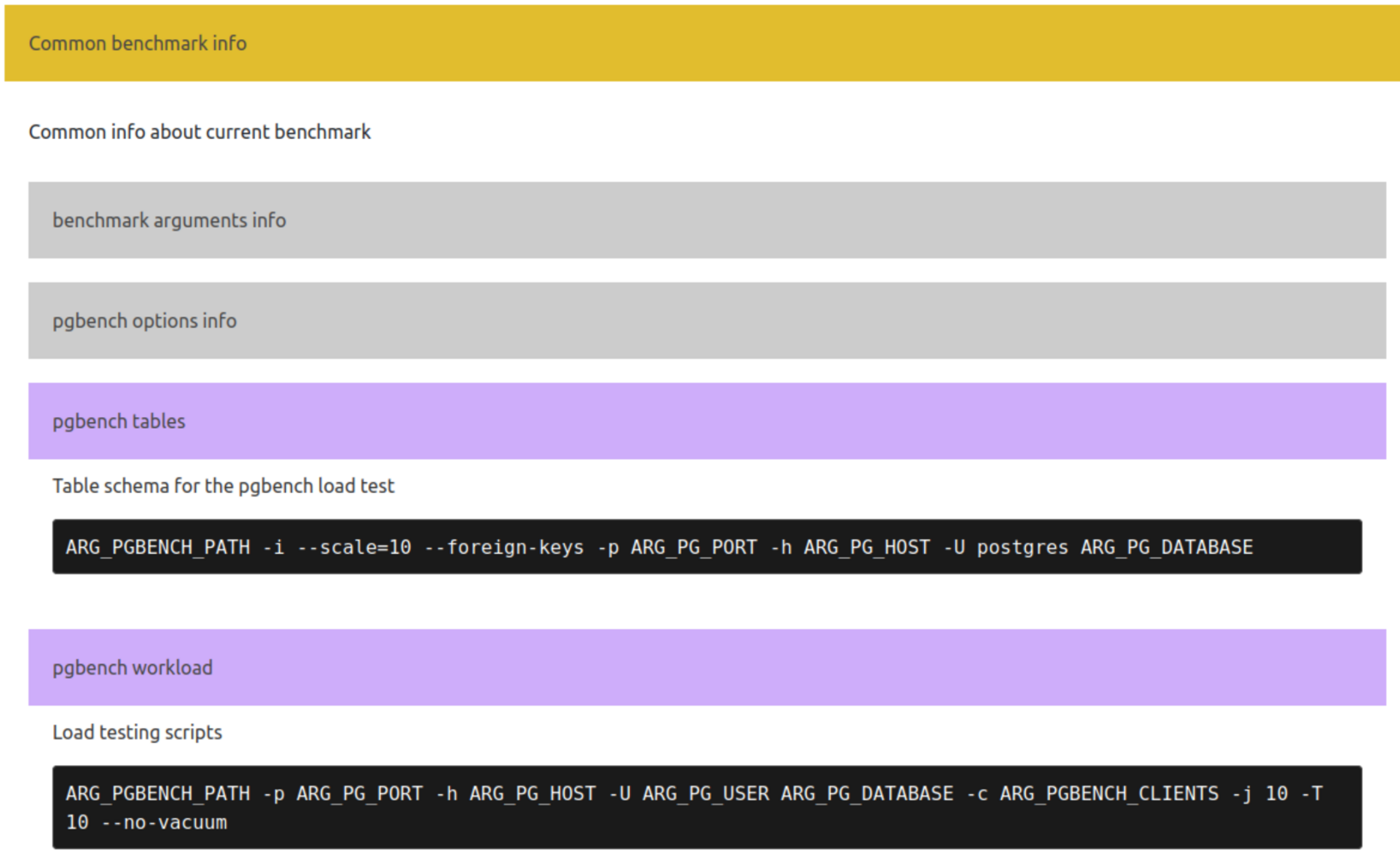
Итерации запуска pgbench будут отображены в разделе описания бенчмарка:
Конфигурация пользовательских параметров pg_perfbench описана в документации.
Итерации запуска pgbench будут отображены в разделе описания бенчмарка:
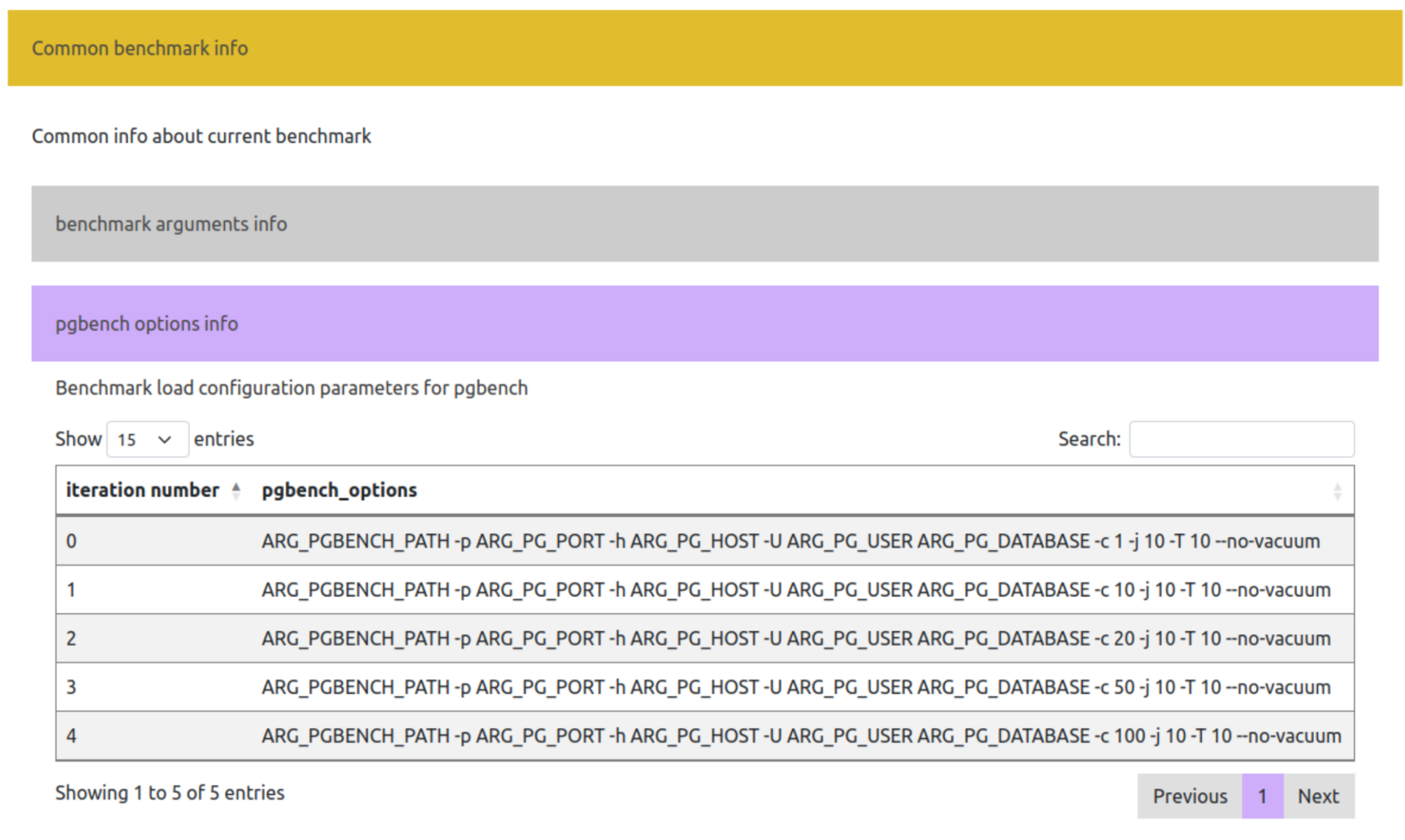
Поскольку используются стандартные запросы нагрузки pgbench, скрипты инциализации и нагрузки будут отображены в виде команд pgbench:
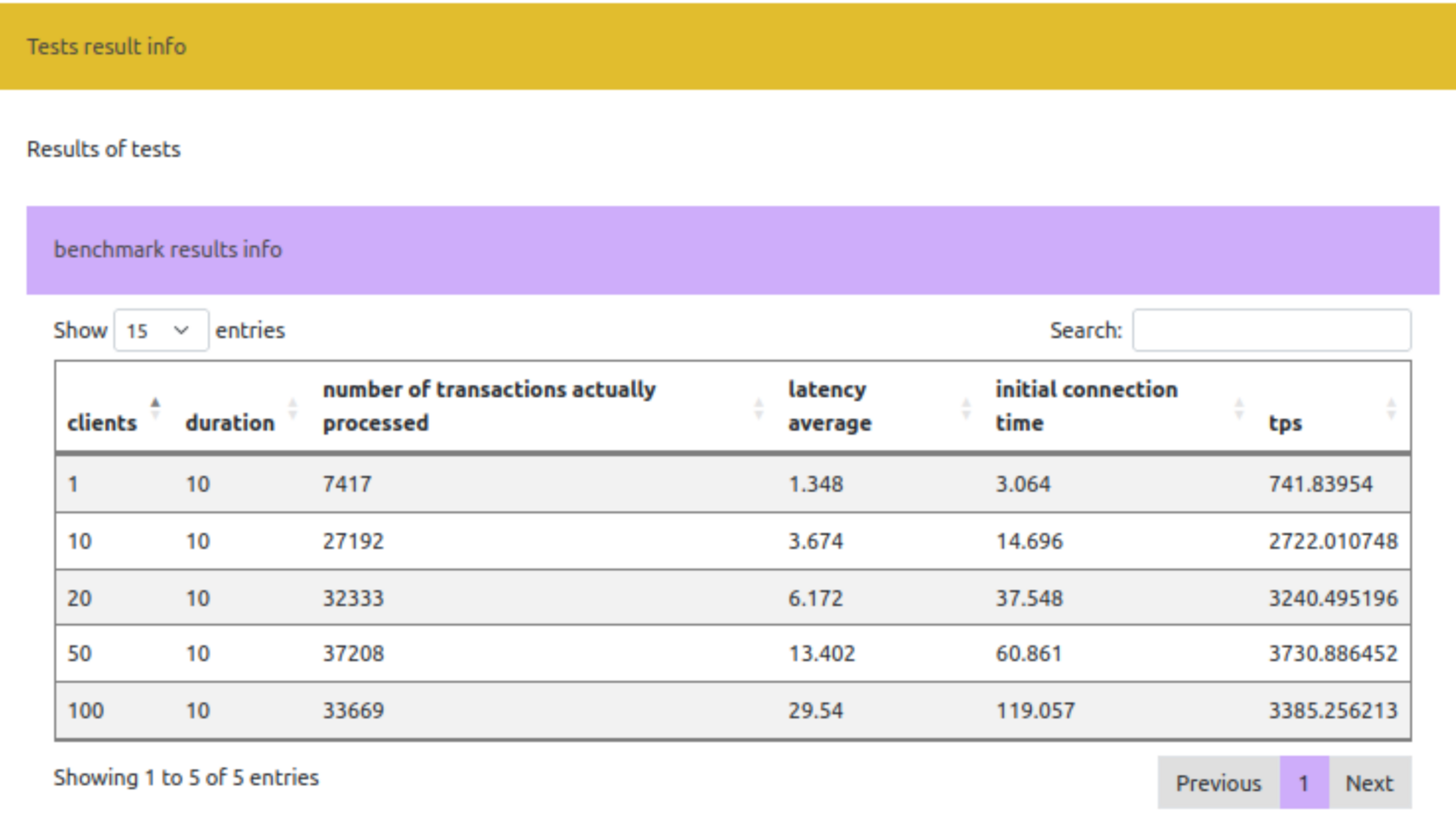
Результат нагрузочного тестирования БД
Данные pgbench удобно представлять в табличном формате, где каждая строка — это одна итерация, а столбцы соответствуют ключевым метрикам:
После этого на графике можно сравнить итерации по TPS (вертикальная ось — TPS, горизонтальная ось — число клиентов):
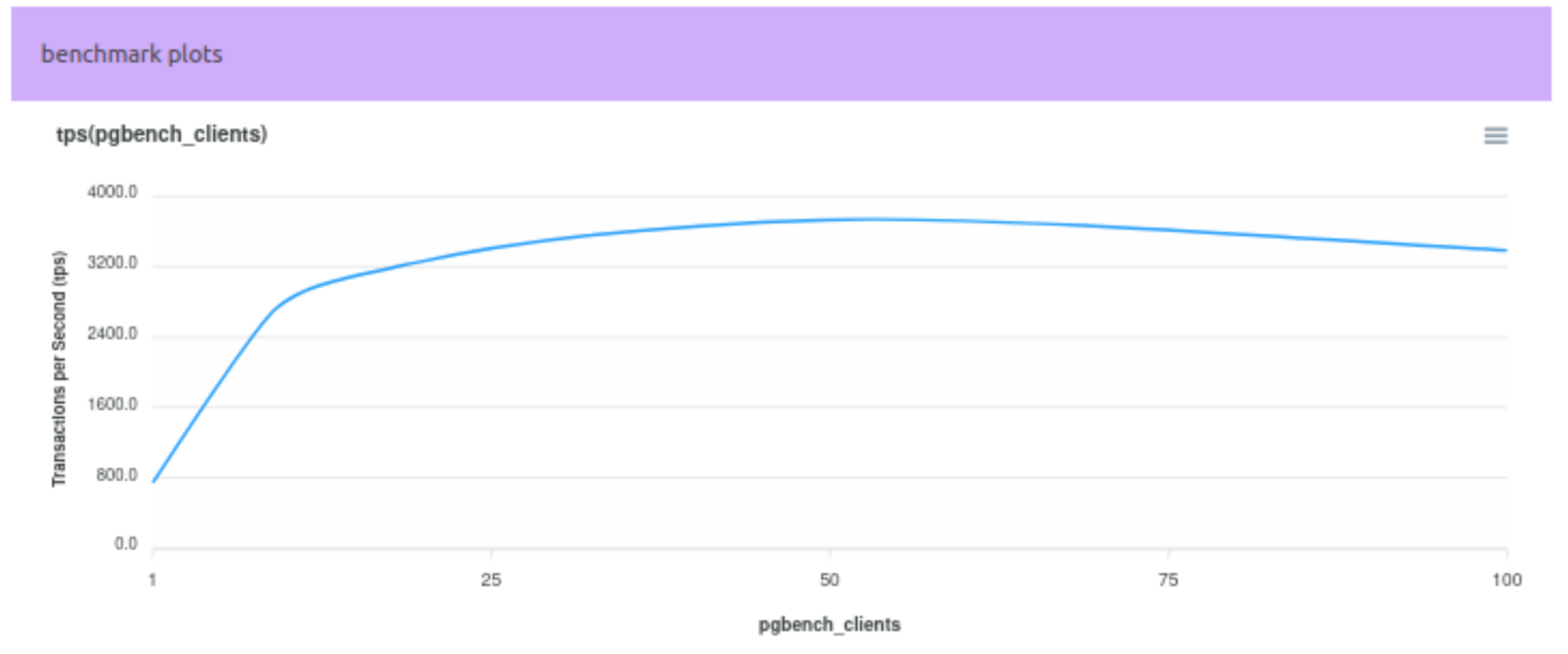
В итоге, автоматизация сбора всей информации и превращение ее в удобную форму (JSON + HTML, графики, таблицы) существенно упрощает не только анализ, но и совместную работу над проектом. Можно быстрее воспроизводить тесты, сопоставлять результаты и находить узкие места в производительности PostgreSQL, не тратя время на выяснение того, что же именно было протестировано и в каких условиях.
Сравнение отчетов
В практике тестирования и анализа производительности PostgreSQL часто возникает необходимость сопоставить несколько результатов нагрузочных испытаний. Это может быть применимо для следующих сценариев:
- сравнение поведения одной и той же базы данных на разных серверах;
- проверка того, как влияют изменения postgresql.conf на итоговую пропускную способность (TPS) и задержку (Latency).
Утилита pg_perfbench предоставляет механизм сравнения уже готовых отчетов в режиме --mode=join. Смысл его работы сводится к тому, чтобы:
- Убедиться, что мы действительно сравниваем соответствующие окружения (одинаковые версии PostgreSQL, схожие системные параметры, тот же набор расширений и т. д.).
- После проверки совпадения ключевых элементов формируется единственный «сведенный» отчет, где можно увидеть разницу в настройках и итогах бенчмарков.
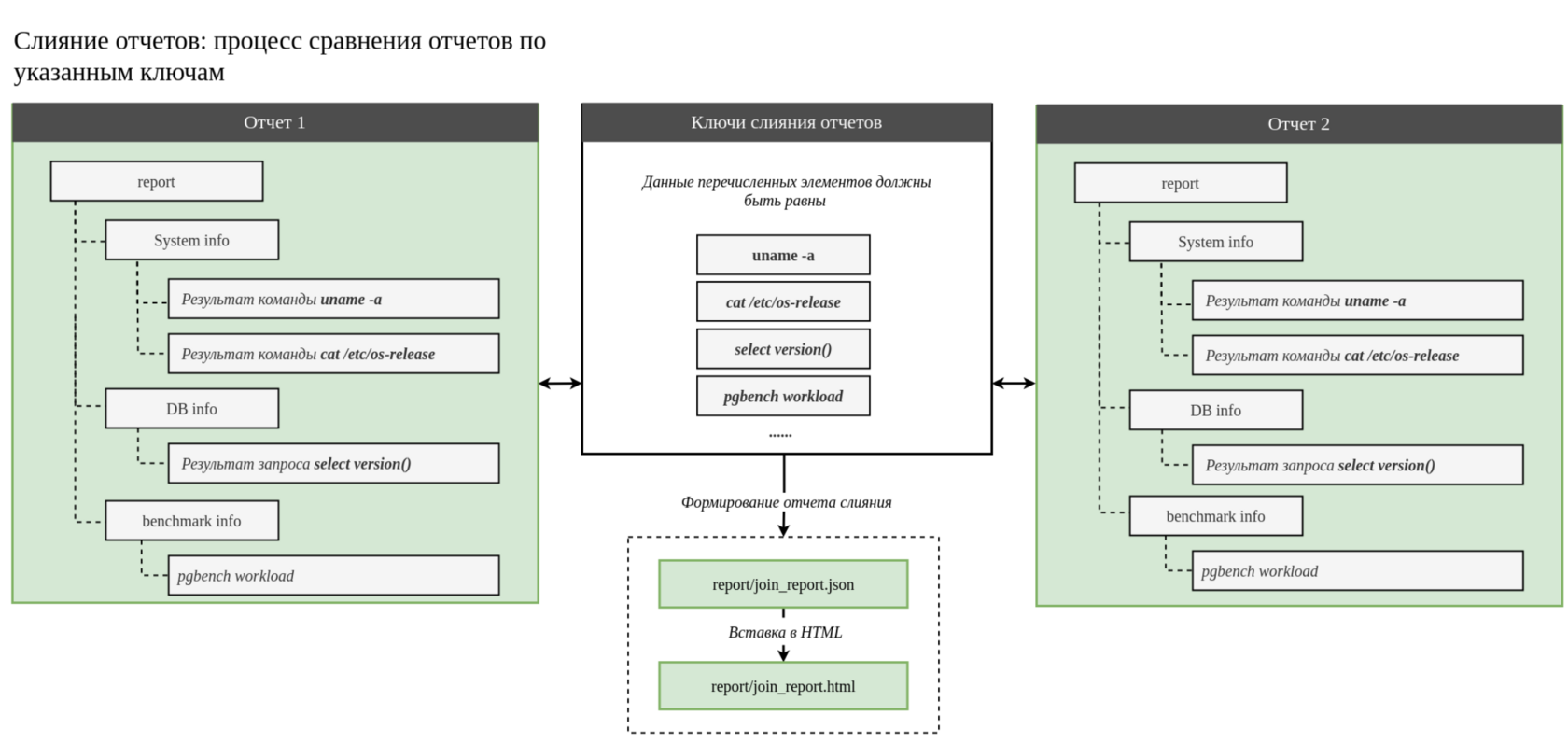
JSON-файл с ключами, по которым будет происходить сопоставление данных из разных отчетов, может иметь структуру следующего вида:
{
"description": <Описание решаемой задачи>,
"items":
[
"sections.system.reports.sysctl_vm.data",
"sections.system.reports.total_ram.data",
"sections.system.reports.cpu_info.data",
"sections.system.reports.etc_fstab.data",
"sections.db.reports.version_major.data",
"sections.db.reports.pg_available_extensions.data",
"sections.db.reports.pg_config.data",
"sections.benchmark.reports.options.data",
"sections.benchmark.reports.custom_tables.data",
"sections.benchmark.reports.custom_workload.data"
]
}Поле "items" содержит массив полей объекта, представляющего структуру отчета. По этим полям будет проверяться равенство значений. Если же окажется, что какие-то из обязательных для сравнения айтемов различаются (например, CPU на одном сервере отличается от другого, или используются разные версии PostgreSQL), утилита прервет процесс слияния и выведет сообщение об ошибке. Это защищает от некорректных сравнений, когда результаты просто не имеют смысла сопоставлять напрямую.
Пример лога:
Пример лога:
2025-03-28 16:31:02,285 INFO root : 218 - Loaded 2 report(s): benchmark-ssh-custom-config.json, benchmark-ssh-default-config.json
2025-03-28 16:31:02,286 ERROR root : 190 - Comparison failed: Unlisted mismatch in 'cpu_info'
reference report - benchmark-ssh-custom-config
comparable report - benchmark-ssh-default-config
2025-03-28 16:31:02,286 ERROR root : 222 - Merge of reports failed.
2025-03-28 16:31:02,286 ERROR root : 317 - Emergency program termination. No report has been generated.Сравнение производительности БД с разными настройками postgresql.conf
Одно из наиболее распространенных применений — проверить эффект от изменения настроек PostgreSQL. Рассмотрим простой сценарий, когда мы имеем два конфигурационных файла:
postgresql_1.conf:
.....
shared_buffers = 166MB
work_mem = 10000kB
maintenance_work_mem = 20MB
effective_cache_size = 243MBpostgresql_2.conf:
.....
shared_buffers = 90MB
work_mem = 5000kB
maintenance_work_mem = 10MB
effective_cache_size = 150MBЦель — понять, как меняется пропускная способность при изменении параметров конфигурации. Нужно запустить pg_perfbench с этими двумя конфигурациями, как описано в главе выше (каждый запуск измерения формирует отдельный отчет). Подробнее настройка пользовательских параметров описана в документации.
Для слияния двух отчетов указываем JSON со списком "items", которые не включают настройки pg_settings (pg_perfbench/join_tasks/task_compare_dbs_on_single_host.json):
Для слияния двух отчетов указываем JSON со списком "items", которые не включают настройки pg_settings (pg_perfbench/join_tasks/task_compare_dbs_on_single_host.json):
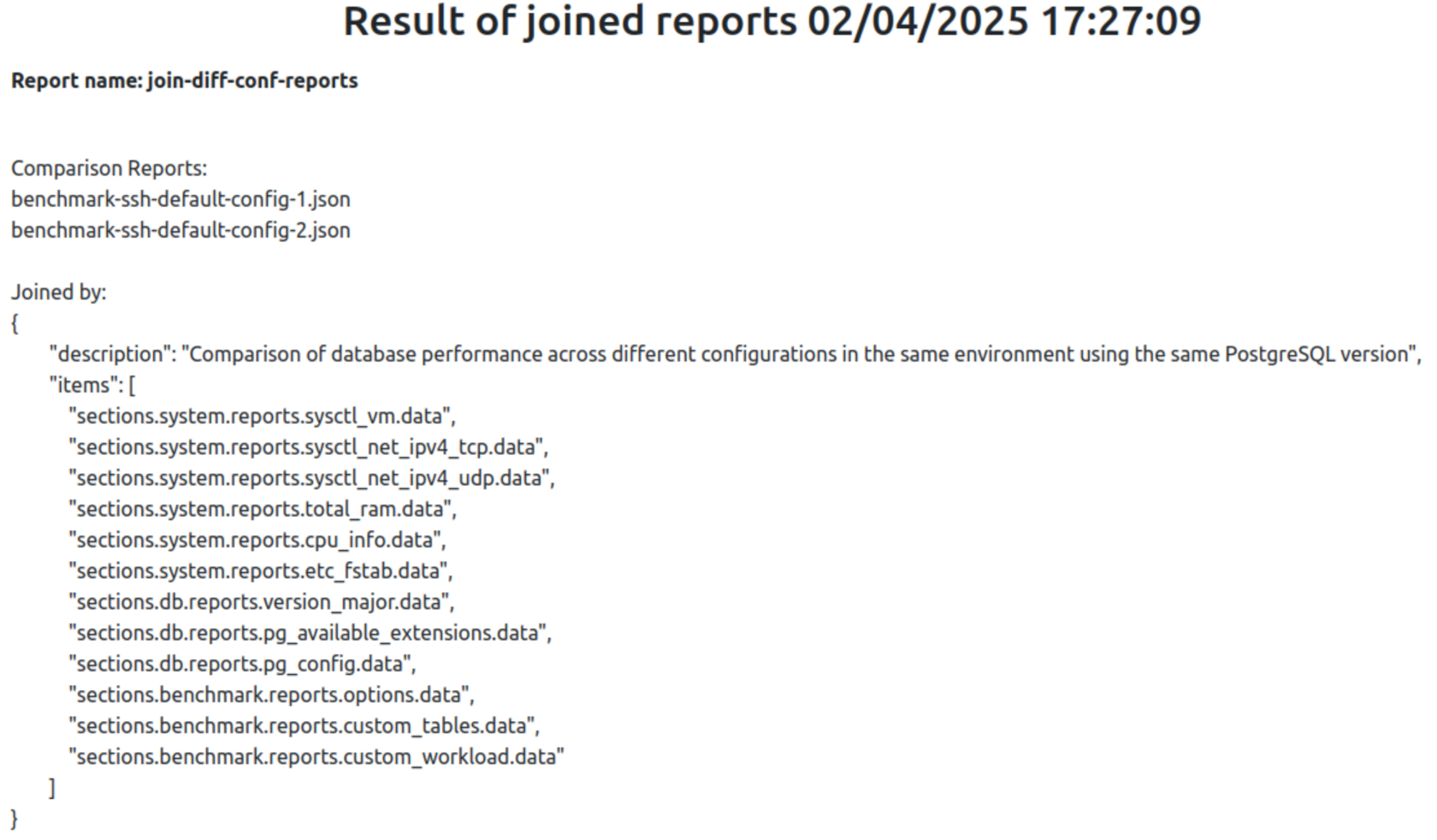
{
"description": "Comparison of database performance across different configurations in the same environment using the same PostgreSQL version",
"items": [
"sections.system.reports.sysctl_vm.data",
"sections.system.reports.sysctl_net_ipv4_tcp.data",
"sections.system.reports.sysctl_net_ipv4_udp.data",
"sections.system.reports.total_ram.data",
"sections.system.reports.cpu_info.data",
"sections.system.reports.etc_fstab.data",
"sections.db.reports.version_major.data",
"sections.db.reports.pg_available_extensions.data",
"sections.db.reports.pg_config.data",
"sections.benchmark.reports.options.data",
"sections.benchmark.reports.custom_tables.data",
"sections.benchmark.reports.custom_workload.data"
]
}Теперь при запуске команды
python -m pg_perfbench --mode=join \
--report-name=join-diff-conf-reports \
--join-task=task_compare_dbs_on_single_host.json \
--input-dir=/pg_perfbench/reportутилита проверит соответствие указанных параметров: одинаковый CPU, одинаковый объем оперативной памяти (по крайней мере тот, который задокументирован в отчетах), одна и та же мажорная версия PostgreSQL, совпадающий набор расширений и т. д. В случае успешного сопоставления утилита сформирует объединенный отчет, а при обнаружении несовпадений в перечисленных items выведет сообщение об ошибке. В журнале процесса будут отображены логи со списком загруженных отчетов и результатом слияния:
python -m pg_perfbench --mode=join \
--report-name=join-diff-conf-reports \
--join-task=task_compare_dbs_on_single_host.json \
--input-dir=/pg_perfbench/report
2025-03-28 16:53:31,476 INFO root : 55 - Logging level: info
.....
#-----------------------------------
2025-03-28 16:53:31,476 INFO root : 211 - Compare items 'task_compare_dbs_on_single_host.json' loaded successfully:
sections.system.reports.sysctl_vm.data
sections.system.reports.sysctl_net_ipv4_tcp.data
sections.system.reports.sysctl_net_ipv4_udp.data
sections.system.reports.total_ram.data
sections.system.reports.cpu_info.data
sections.system.reports.etc_fstab.data
sections.db.reports.version_major.data
sections.db.reports.pg_available_extensions.data
sections.db.reports.pg_config.data
sections.benchmark.reports.options.data
sections.benchmark.reports.custom_tables.data
sections.benchmark.reports.custom_workload.data
.....
2025-03-28 16:53:31,481 INFO root : 99 - The report is saved in the 'report' folder
2025-03-28 16:53:31,481 INFO root : 322 - Benchmark report saved successfully.Join-отчет будет содержать:
- перечисления сравниваемых отчетов и параметров слияния:
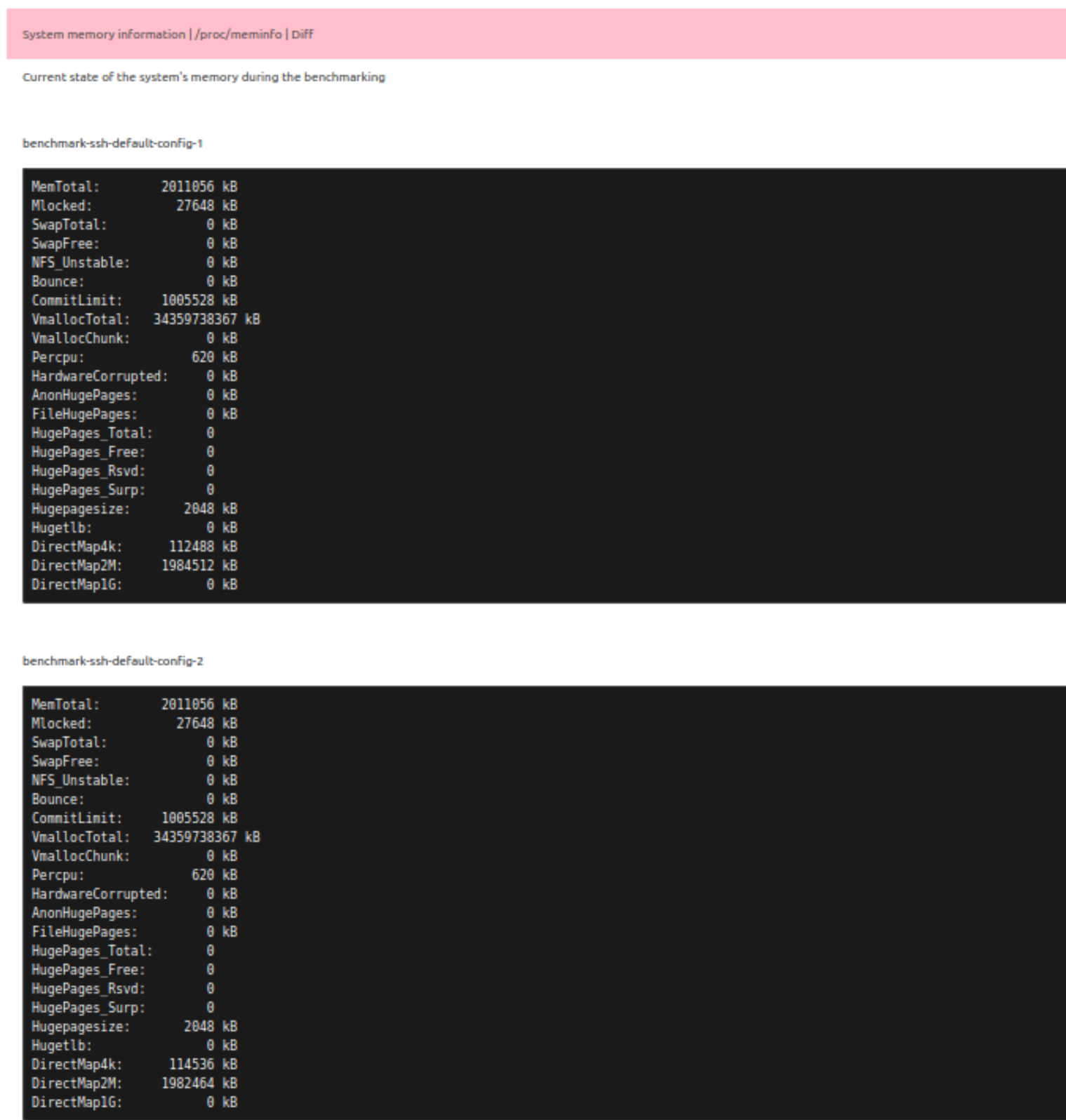
- Совпадения данных system минимум по элементам, перечисленным в списке для слияния. Если у элементов, не указанных в списке слияния, в сравниваемых отчётах есть различия в поле data, то в итоговом Join-отчёте вкладка для такого элемента будет помечена особым цветом и словом Diff. В самой вкладке будут отображены результаты соответствующих элементов из всех сравниваемых отчётов:

- Совпадения данных DB по параметрам слияния:

- Конфигурацию нагрузки pgbench. Отличия в конфигурации пользовательских параметров состоят в разных конфигурациях(postgresql.conf) БД отчетов:
- Раздел results с отображением разницы производительности между отчетами бенчмарков:
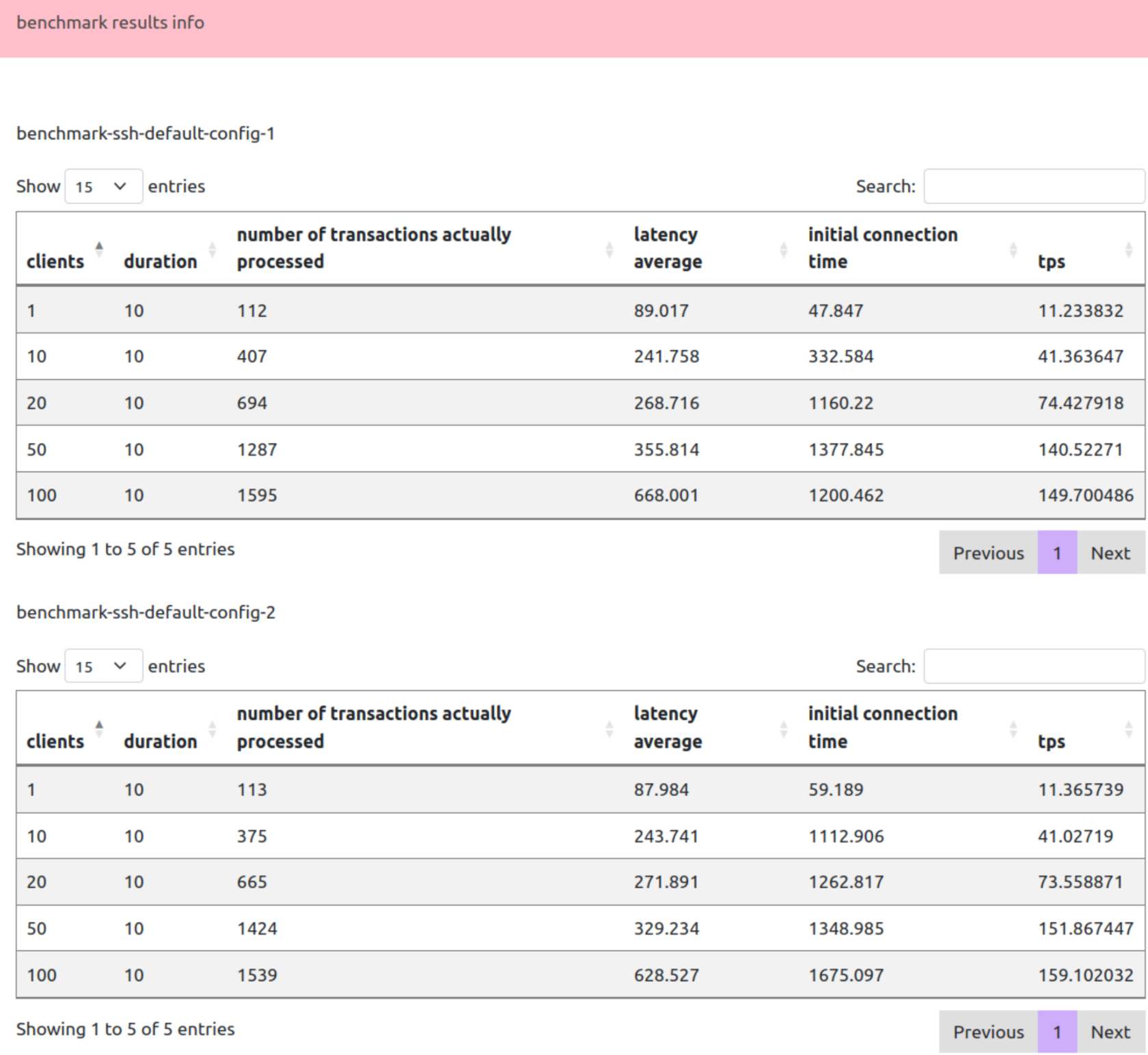
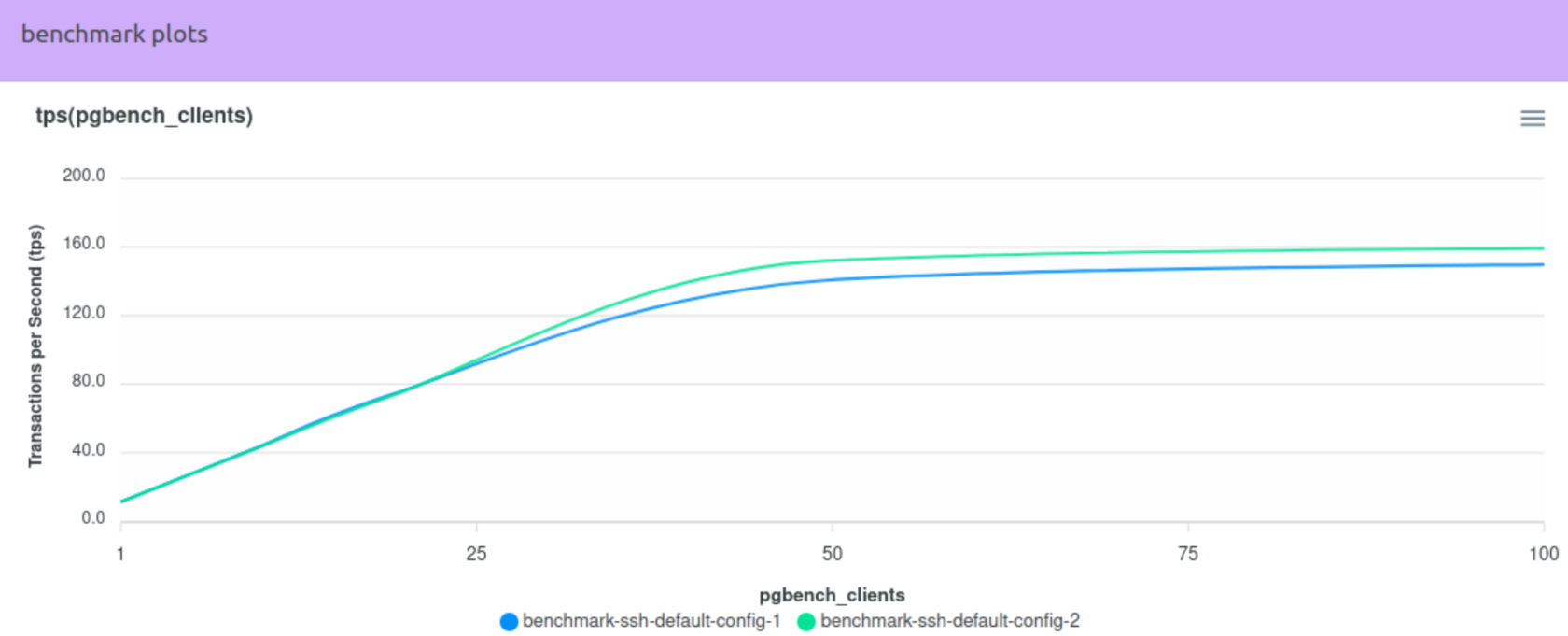
На диаграмме можно быстро оценить разницу бенчмарков по tps:
Заключение
Использование инструмента pg_perfbench позволяет:
- Избежать пропущенных деталей окружения: все важные параметры аппаратного уровня (CPU, RAM, диски, сетевые настройки) и конфигурации Tantor Postgres или другой БД на базе PostgreSQL (версия, расширения, основные и второстепенные параметры, ключевые утилиты) автоматически собираются в ходе тестирования, что исключает риск неполноты данных при анализе.
- Сократить время на подготовку и повторное воспроизведение тестов: больше не требуется вручную описывать каждую деталь тестового окружения, а затем повторять все ручные шаги. Параметры нагрузки (число клиентов, время теста, команды pgbench) и ключевые системные параметры автоматически фиксируются в одном отчете.
- Упростить анализ и сравнение результатов: информация собирается в структурированном формате (JSON и/или HTML), в котором легко ориентироваться. Визуальное представление (графики, таблицы) позволяет быстро оценивать динамику показателей (tps), а встроенный функционал join облегчает сравнение нескольких отчетов.
- Обеспечить воспроизводимость экспериментов: при необходимости вернуться к предыдущим замерам и заново запустить их в тех же условиях не придется восстанавливать все параметры вручную — в отчете уже содержатся все важные настройки и сведения об окружении.
- Унифицировать подход к нагрузочному тестированию: pg_perfbench предоставляет единый интерфейс для подключения к различным типам окружений (локальная машина, SSH, Docker) и интеграцию с pgbench. Это повышает гибкость и дает возможность централизованно управлять процессом тестирования.
Таким образом, pg_perfbench способствует формированию прозрачного, достоверного и воспроизводимого процесса нагрузочного тестирования PostgreSQL, значительно упрощая анализ результатов, повторный запуск сценариев и их сопоставление между собой.
Рассмотренный проект находится в репозитории https://github.com/TantorLabs/pg_perfbench








