Материал подготовлен по итогам выступления Александра Симонова, технического руководителя направления развития «1С» компании «Тантор Лабс», на конференции INFOSTART Tech Event в октябре 2024 г. Проведенный мастер-класс послужил задаче наглядно продемонстрировать, что несколько тысяч пользователей в базе «1С» на СУБД Tantor в настоящее время не являют собой ничего сверхъестественного, такой показатель становится нормой.
В рамках мастер-класса был запущен нагрузочный тест на 3000 пользователей, в это время спикер рассказал о следующем:
- что это за тест и какое «железо» нужно для его проведения;
- как ведет себя оборудование во время теста (с эмуляцией проблем производительности);
- примеры проблем, которые позволяют выявить нагрузочные тесты.
О тесте

Тест был проведен на конфигурации «1С: Документооборот» редакции 2.1, профиль нагрузки – смешанный. Данный тест не является синтетическим, а написан под конкретного заказчика согласно его профилю нагрузки, определенному в ходе исследования. Разработала тест компания «ИТ-Экспертиза».
Какие операции выполняют виртуальные пользователи:
- 50% пользователей выполняют OLTP-операции: записывают внутренние документы, запускают бизнес-процессы, выполняют задачи, открывают формы, сопутствующие выполнению этих операций. Средняя длительность данных ключевых операций – до 3 с.;
- 40% формируют отчеты, средняя длительность – 4–120 с.;
- 10% работают с обработками – средняя длительность 5–15 с.
Стенд

Стенд состоит из следующих компонентов:
Сервер приложений
- 3 ВМ по 32 CPU, 128 Гб RAM, 300 Гб СХД;
- платформа 8.3.23.2157, ОС Astra Linux 1.7.5;
- 1 центральный сервер и 2 рабочих. На центральный через ТНФ вынесены сервисы журнала регистрации, полнотекстового поиска и лицензирования. Вообще, конечно, под сервис лицензирования правильно выделять отдельный сервер, но в данном тесте мы этого не стали делать.
Все остальные настройки кластера – по умолчанию.
Сервер СУБД
- Физический сервер Tantor XData v.1.0 c 96 CPU, 374 Гб RAM (c RAM есть нюанс, который рассмотрен ниже);
- 2 физических разных диска: основной – data-каталог, где находится сама база данных, и второй – вынесены WAL, а temp_tablespaces – нет (ниже отмечено, к чему это может привести);
- СУБД «Tantor Special Edition 1C» 16.2.1, ОС Astra Linux 1.7.5.
Терминальные сервера
- 10 ВМ с характеристиками 16 CPU, 64 Гб ОЗУ, 100 Гб диск;
- на каждой ВМ запускаются 5 терминальных пользователей, каждый из которых открывает по 60 ВРМ (сеансов «1С»).
Настройки СУБД Tantor
Думаю, что уже многие пользователи умеют настраивать СУБД Tantor. Я лишь расскажу о некоторых нюансах, и первый из них – это JIT. Данная настройка должна быть выключена: именно на этом тесте параметр дает деградацию более 10%, а также приводит к повышенной утилизации процессора. Вот пример, как в листинге плана запроса отображается, какое количество времени «съедает» JIT, при этом пользы от него никакой:

Это реальный пример запроса из данного нагрузочного теста. Запрос выполнялся 10.5 секунд, из них половину времени заняла JIT-компиляция. Для чего она? Документация гласит:
JIT-компиляция – процедура преобразования интерпретируемого варианта исполнения программы в программу на языке процессора. Например, вместо «WHERE a.col = 3» можно сгенерировать функцию, которую сможет выполнять непосредственно процессор, так что она будет выполняться быстрее.
В «1С» эффекта от данного функционала нет. Если у вас включен JIT, отключите его, и ваша система станет работать быстрее. Начиная с версии 15.6.2 в «Tantor SE 1C» мы изменили значение JIT по умолчанию с ON на OFF, чтобы уменьшить у клиентов вероятность неоптимальной настройки СУБД под «1С».
Второй нюанс – это как раз 2 настройки планировщика:
- join_collapse_limit = 20;
- from_collapse_limit = 20.
Данные параметры позволяют СУБД Tantor при планировании перебирать большее количество вариантов соединения таблиц. Это может позволить как можно раньше выбрать соединение наиболее селективных таблиц, которые сильно сократят выборку. А, как мы знаем, в запросах «1С» количество соединений более 10 может встречаться часто. Ниже, например, запрос, в котором 15 соединений. Если параметры стоят в 10, то мы получаем вот такой план. На скриншоте выделен отбор по регистратору регистра сведений – отбор селективнейший, но Postgres решает наложить его в конце, т.к. при переборе различных вариантов соединения не был учтен вариант, что отбор можно наложить сразу. Если увеличить до 20, то он находит оптимальный вариант.

Ход нагрузочного теста

Открываем базу «1С» и удостоверяемся, что тест успешно запустился и выполняется. Давайте посмотрим, как ведет себя оборудование.
Показатели оборудования

На сервере СУБД нагрузка растет по мере запуска сценариев, и в среднем в ходе теста по CPU будет утилизация 30-40%. Выше я писал про нюанс с RAM, что ОЗУ на СУБД выделено 378 Гб, а тут в графике 768 Гб. Дело в том, что Tantor XData – это физическая машина, и поэтому мы выделили часть памяти под Huge pages (огромные страницы), чтобы для СУБД Tantor оставить ровно 378 Гб. В настройках СУБД Tantor огромные страницы явно отключены (huge_pages=off), и он не сможет использовать выделенную для них память.

На сервере приложений в момент запуска 3 тысяч тонких клиентов были пики утилизации CPU до 100%.

Аналогичные пики утилизации CPU были и на терминалах, где работают тонкие клиенты. На итоговый отчет производительности эти пики никак не повлияют, т.к. они были до фактического старта выполнения ключевых операций.
В чем основная суть этого дашборда? Чтобы нагрузочный тест считался успешно проведенным, он не должен «упираться» в оборудование как на СУБД, так и на СП, и на терминальных нагрузчиках. Иначе результаты нагрузочного теста не будут достоверными, и каждый раз вы будете получать различные результаты по среднему времени выполнения ключевых операций, а они могут сильно «скакать». Допустим, вы сравниваете 2 различные сборки СУБД Tantor: 15 и 16. Разное время ключевых операций наведет вас на мысль, что что-то поменялось в самих механизмах СУБД, хотя по факту их время отличается по другим причинам (из-за утилизации оборудования). Но есть исключение: допустим, у нас есть небольшие пики по CPU. Тут в тесте важно учесть, что операции должны проходить в течение всего теста равномерно, чтобы оказалось, что они все пришлись на пик. Если они распределены равномерно, то в пике они могли выполняться дольше, чем обычно, за счет утилизации ресурсов, но во всех остальных случаях время будет корректным и в итоге среднее время получится адекватным.
Вернемся к СУБД, а именно, к графику утилизации диска:

Что же так утилизирует диск? Чтобы ответить на этот вопрос, я делал этот тест, но с выносом временных таблиц на отдельный диск (за это в СУБД Tantor отвечает параметр temp_tablespaces) и без выноса временных таблиц получил следующие результаты.

Из графика видно, что утилизируют диск именно временные таблицы. Но почему, если они должны создаваться в оперативной памяти?
Дело во внутреннем устройстве СУБД Tantor: независимо от того, какое значение у вас установлено в параметре temp_buffers при создании временной таблицы на диске создается файл размером 8 Кб на случай, если вдруг размер не временной таблицы будет превышать значение в temp_buffers, и ее придется «скидывать» на диск. Так происходит при создании каждой временной таблицы, поэтому и создается такая нагрузка. И именно поэтому для высоконагруженных систем рекомендуется выносить временные таблицы через параметр temp_tablespaces на отдельный диск или диски.
Мы планируем доработать СУБД «Tantor Special Edition 1C» так, чтобы файл на диске создавался, только когда временная таблица «сбрасывается» на диск. Это поможет значительно уменьшить нагрузку.
Эмулируем проблемы
Давайте теперь подумаем о случаях, которые могут быть в реальном продуктиве с большим количеством пользователей. Создадим проблемы сами и посмотрим, как они повлияют на APDEX.
Большая временная таблица
Давайте поместим во временную таблицу 400 млн строк. Как обычно бывает: пользователь написал в консоли запрос, запустил его, он завис, и пользователь закрывает свой сеанс в диспетчере задач, думая, что никто ничего не узнает. Но по факту это не так, запрос продолжит выполняться.
Такая временная таблица будет размером больше, чем значение temp_buffers (256 Мб), поэтому СУБД Tantor при ее создании сделает следующее:
- 256 Мб данной временной таблицы действительно будет размещено в оперативной памяти.
- Остальную часть временной таблицы начнет «сбрасывать» на диск файлами по 1 Гб.
Запускаем запрос и видим, что действительно начинает утилизироваться место на диске: растет размер data-каталога, где хранится сама база данных и куда также «сбрасывается» временная таблица с файлами по 1 Гб:

Есть еще вариант: вынести временные таблицы в оперативную память через temp_tablespaces – в этом случае data-каталог расти не будет, т.к. временная таблица будет размещаться в оперативной памяти. Но, как правило, ее меньше, чем места на диске, и поэтому в случае создания огромной временной таблицы память может закончиться. Такой сеанс получит ошибку:
Все другие сеансы, которые в этот же момент хотели поместить данные во временные таблицы, вызовут аналогичную ошибку и аварийно завершатся.
Но место в каталоге временных таблиц данные сеансы, которые завершились аварийно, удерживать не будут, поэтому все остальные сеансы, которые в момент проблемы не пытались поместить временную таблицу в оперативную память, продолжат успешно работать, и их последующие попытки поместить данные во временные таблицы завершатся успешно.
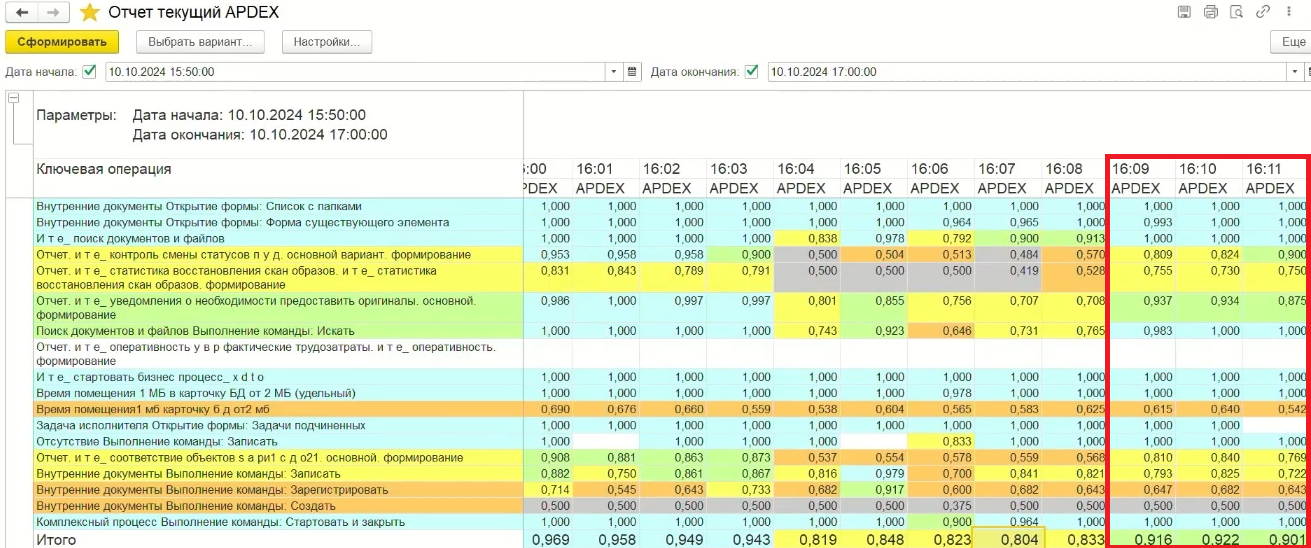
Давайте посмотрим, как создание такой временной таблицы повлияет на показатели APDEX. Я написал отчет «Текущий APDEX», который рассчитывает и показывает APDEX по каждой ключевой операции в разрезе минут:
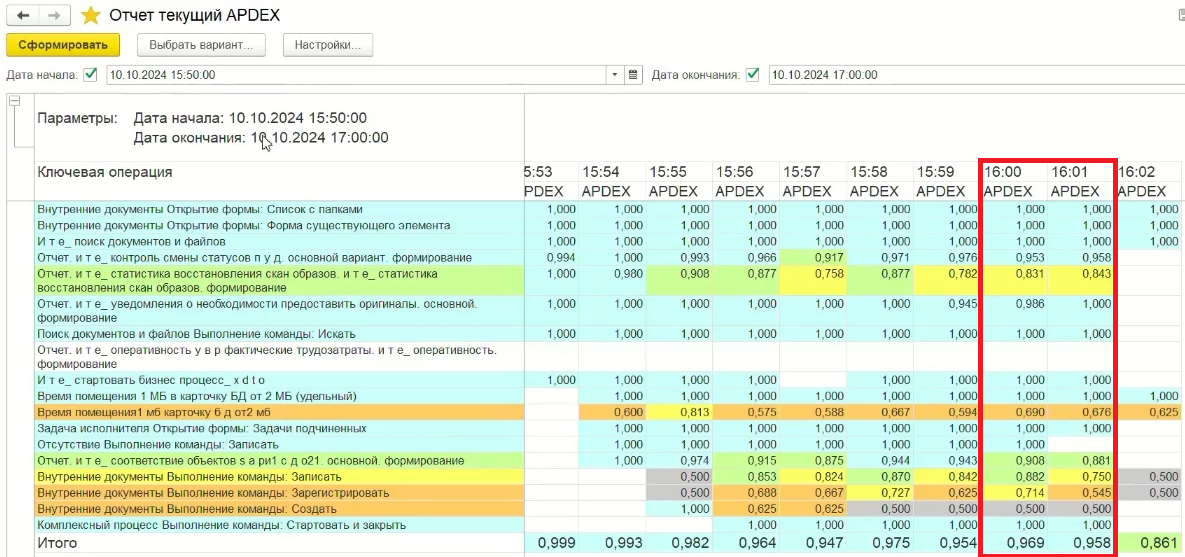
Как видим, на производительности это никак особо не отразилось. Дело в том, что у нас еще есть запас в дисковой подсистеме, которая в среднем утилизирована на 40-50%:
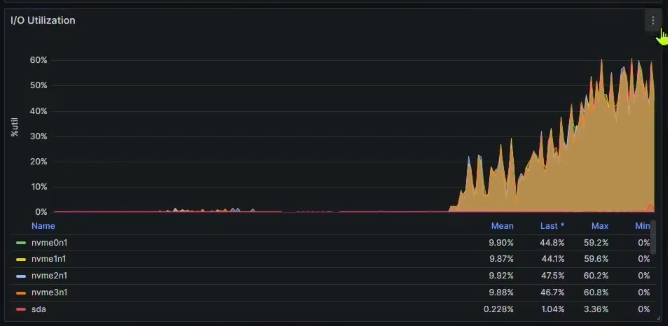
Завершаем данный сеанс и далее сэмулируем еще одну проблему производительности, когда запускается неоптимальный функционал, утилизирующий большое количество ресурсов.
Неоптимальные запросы к базе данных
Запустим 50 фоновых заданий, которые будут выполнять запрос, который выполняется около 3 минут. По задумке, сейчас процессор на СУБД будет утилизирован на 100%, и мы посмотрим, как это скажется на APDEX.
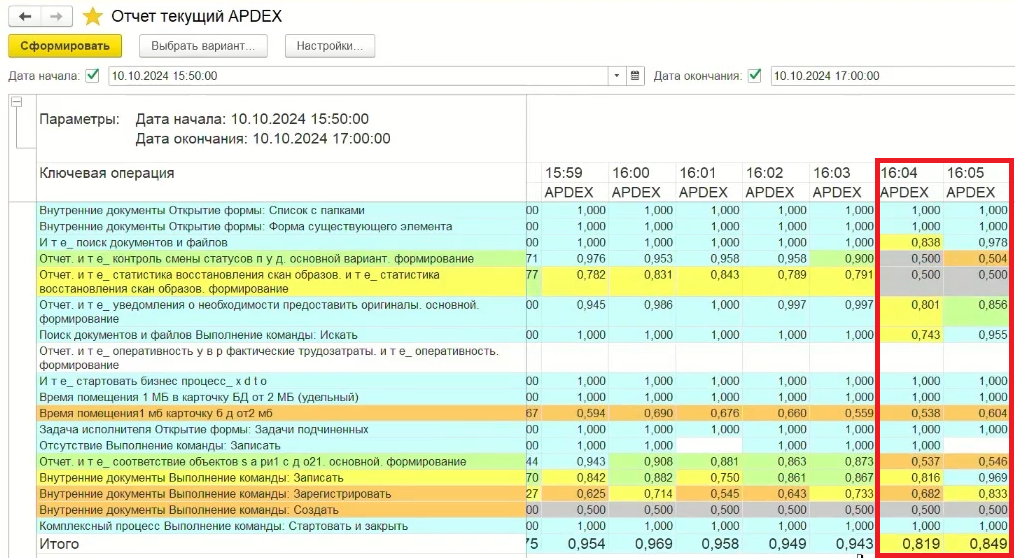
Он становится хуже, опускается до уровня «удовлетворительно», это и есть проблема. Помимо того, что процессор утилизирован на 100%, начинает расти количество соединений на СУБД. Мы можем это увидеть на графике Sessions в платформе Tantor:
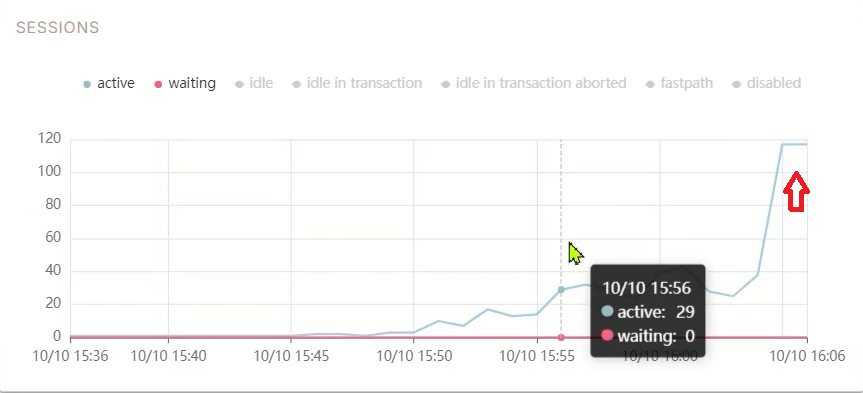
Вообще, этот показатель Sessions (количество активных сессий на СУБД) – отличный триггер для мониторинга. Он может показывать не только проблемы с процессором, но и другие, например, с диском или памятью. Ведь в случае больших очередей к диску или нехватки памяти сессии начнут ожидать освобождения ресурсов, что приведет к росту их количества.
На прошлом месте работы у нас триггер был настроен так: мы понимали, какое количество активных соединений СУБД для нашей базы являлось нормальным – 40. Если количество активных сессий становилось более 40 и так держалось 5 минут, то срабатывал алерт, что есть проблема и необходимо разобраться, что происходит с системой. Он очень хорошо нам помогал обнаруживать проблемы, и, как правило, после его срабатывания через какое-то время приходил представитель бизнеса и жаловался на производительность. Рекомендую использовать этот показатель для алертинга.
Вот так во время запуска фоновых заданий был нагружен процессор:
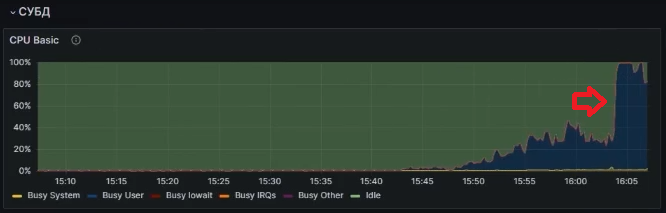
После их окончания мы видим, что APDEX пришел в норму, когда освободились ресурсы процессора, которые нужны нашим сеансам нагрузочного теста:
Завершение нагрузочного теста
Сейчас мы прервем наш нагрузочный тест, чтобы посмотреть на итоговый отчет APDEX:

Можно подытожить, что на Tantor XData 1С прекрасно работает с несколькими тысячами пользователей. Проблемы для работы СУБД может создавать функционал приложения, за которым нужно пристально следить для поддержания качества работы высоконагруженных систем. Вообще, стоит привыкнуть, что с каждым годом количество таких высоконагруженных инсталляций 1С на решениях Tantor будет только расти.








